400 128 6709

行业新闻
 发布时间:2023-06-11
发布时间:2023-06-11 点击次数:
点击次数: 2025-06-07 17:42:41 作者:李文雯
每个科幻迷都向往着在未来能像和老朋友对话一样,用寥寥数语发动星际飞船,征服星辰大海;或者拥有钢铁侠的人工智能管家贾维斯,几句对话就能造出一套纳米战甲。其实这个画面离我们并不远——就像 iPhone 中的 Siri 一样同我们触手可及。它的背后是自动语言识别技术(Automatic Speech Recognition)。这项关键技术能将语音转换为计算机可识别的文字或命令,实现便捷、高效、智能的人机交互体验。
而随着深度学习等 AI 技术的发展,语音识别技术已经取得了巨大的进步——不仅识别准确度大大提高,而且能够更好地处理口音、噪声和背景音等问题。但随着技术在生活和业务中的不断应用,仍会遇到一些瓶颈,毕竟从理论研究到实际应用,从论文到产品,需要考虑太多的现实因素。如何让语音识别更好地辅助内容审核?如何让识别动作本身也能像人脑一样,根据对语境的理解,以更低的成本给出更准确的答案?网易智企旗下易盾 AI Lab 给出了新方法。
易盾又出黑科技,智企迈向全世界!
近日,全球语音、声学会议ICASSP 2025 公布了论文入选名单,网易智企旗下易盾 AI Lab 提交的论文成功被录用。今年是第 48 届 ICASSP 大会,也是疫情后的第一届线下大会,虽然大会官方还未公布最后录用了多少篇论文,但论文投递的数量相较往年上升了 50%,达到了惊人的 6,000+。
面对如此激烈的竞争,网易智企易盾 AILab 团队凭借一篇语音识别方向的论文《Improving CTC-based ASRModels with Gated Interplayer Collaboration(基于 CTC 的模型改进,实现更强的模型结构)》脱颖而出,成功拿到了前往希腊罗德岛线下参会的门票。
“GIC”,助力语音识别更进一步
语音识别本质上是语音序列到文字序列的转化,而要完成这样的转化,一般会用到三类模型,CTC、Attention-based 和 RNN-Transducer,它们在完成任务的时候采用了不同的路径:
CTC:基于神经网络模型,在训练过程中通过反向传播来更新模型参数以最小化损失函数。该算法引入了“空白符”来表示无意义字符或者间隔符号。CTC 适合处理输入输出长度相差较大的数据,如语音识别中将声学特征映射为文本;
Attention-based:注意力机制,也是基于神经网络模型,并且使用一种称为“注意力”的技术来对输入进行加权汇聚。在每个时间步骤上,该模型会根据当前状态和所有输入计算出一个分布式权重向量,并将其应用于所有输入以产生一个加权平均值作为输出。这种方式可以使得模型更好地关注与当前预测相关的部分信息;
RNN-Transducer:转录器,这个算法结合了编码器-解码器框架和自回归建模思想,在生成目标序列时同时考虑源语言句子和已生成部分目标语言句子之间的交互作用。与其他两种方法不同,RNN-Transducer 没有明确区分编码器和解码器阶段,并且直接从源语言到目标语言进行转换,因此可以同时考虑源语言句子和已生成部分目标语言句子之间的交互作用。
相比后两者,虽然 CTC 具有天然的非自回归解码性质,解码速度相对快很多,但依然有着性能劣势:
1. CTC 算法设置了条件独立性假设,即 CTC 假设每个时间步的输出之间是独立的。这对语音识别任务来说并不合理,假如说“ji rou”这个发音,在不同的上下文中预测的文字内容应该不一样的。如果上文是“我喜欢吃”,接下来“鸡”的概率应该更高,同理如果上文是“他手臂有”,接下来“肌”的概率应该更高。如果通过 CTC 训练,很容易就会在忽略上文的前提下,输出“我喜欢吃肌肉”这样好笑的文本;
2.从建模的视角来看,Attention-based模型和 RNN-Transducer 模型根据输入和之前时间步的输出预测当前时间步的输出,而 CTC 模型仅仅利用输入来预测当下的输出,在 CTC 模型的建模过程中,文本信息仅仅是作为一种监督信号回传给网络,并没有作为网络的输入显式促进模型的预测。
我们希望能在保留 CTC 解码效率的同时,尽可能地解决以上两点劣势。于是,我们想从 CTC 模型本身出发,设计轻量级的模块给基于 CTC 的模型引入文本信息,使得模型能够整合声学和文本信息,学习到文本序列上下文之间的相互作用,从而缓解 CTC 算法的条件独立性假设。但过程中,我们碰到了两个问题:如何在CTC模型(Encoder +CTC 结构)里注入文本信息?如何自适应地融合文本特征和声学特征?
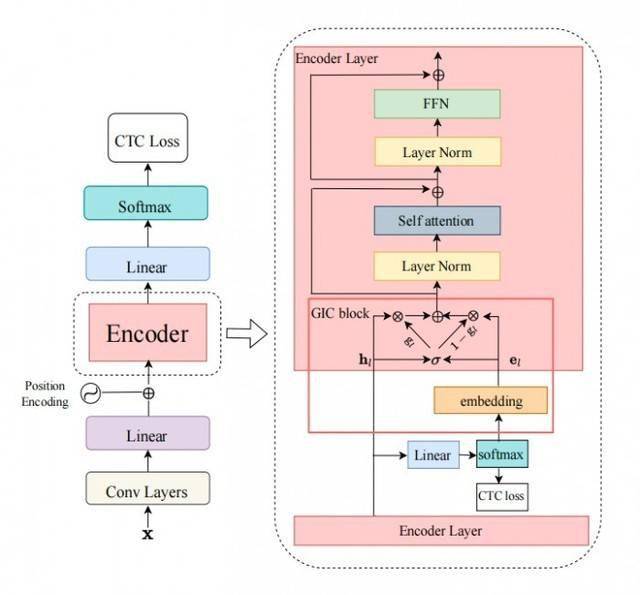
为了实现上述目标,我们设计了 Gated Interlayer Collaboration(简写为GIC)机制。GIC 模块主要包含一个嵌入层(embedding layer)和一个门控单元(gate unit)。其中,嵌入层用于生成每一音频输入帧的文本信息,门控单元用于自适应地融合文本信息和声学信息。
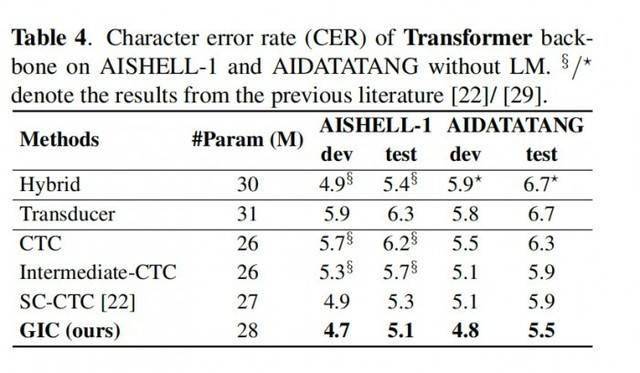
具体地,我们的方法基于多任务学习(Multi-taskLearning)框架,利用编码器模块(Encoder)中间层的输出计算辅助 CTC loss,整个网络的目标函数是最后一层的 CTC loss 和中间层辅助 CTC loss 的加权和。GIC 将网络中间层的预测,即 Softmax 输出的概率分布作为每一帧的软标签,点乘嵌入层矩阵之和作为每一帧的文本表征。最后,生成的文本表征和声学表征通过一个门控单元自适应地融合,成为一个新特征输入到下一层。此时的新特征融合了文本特征和声学特征,使得下一层的 Encoder 模块可以学习到声学序列上下文信息和文本序列上下文信息。整个模型的框架如下图所示:
在 Conformer 和 Transformer 这两个模型上的实验表明:
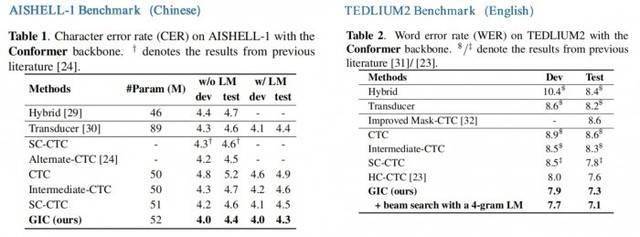
1. GIC 同时支持汉语和英语的场景识别,同时准确度均取得了显著的性能提升;
2. GIC 模型性能超过了同参数规模的Attention-based 和 RNN-transducer 模型,并且具有非自回归解码的优势,带来数倍的解码速度提升;
3. 相对原始的 CTC 模型,GIC 在多个开源数据集有远超 10% 的相对性能提升。
Conformer 模型下的结论
Transformer 模型下的结论
GIC 为 CTC 模型的性能带来了很大的提升。相对原始的 CTC 模型,GIC 模块大约带来2M 的额外参数,其中,计算中间层辅助 CTC loss 所用的线性层与最后一层是共享的,不会带来额外的参数。多个中间层共享嵌入层,带来 256*5000 约等于 1.3M 的参数。此外,多个控制门单元所需的额外参数量为256*256*2*k,总计约0.6M。
领先技术造就先进业务
 Seede AI
Seede AI
AI 驱动的设计工具
 713
查看详情
713
查看详情

论文中的 GIC 已经应用在了网易易盾的内容审核业务中。
作为网易智企旗下一站式数字内容风控品牌,易盾长期专注于数字内容安全风控和反垃圾信息的技术研发和创新。其中,针对以声音作为载体的数字内容,易盾提供了多种音频内容审核引擎,包括歌曲、广播、电视节目、|直播|等各种类型的音频内容,及时检测和过滤含有敏感、违规、低俗,广告内容的语音,从而减少不良内容的社会影响,营造良好的网络环境。
针对有具体语义内容的音频,易盾通过语音识别技术将音频文件中的语音内容转写为文字内容,再利用检测模块分析和处理文本,从而实现对音频内容的自动化审核和过滤。因此,语音识别的准确率与音频内容的审核效率和准确性是息息相关的,会直接影响到客户开展业务的安全与稳定。
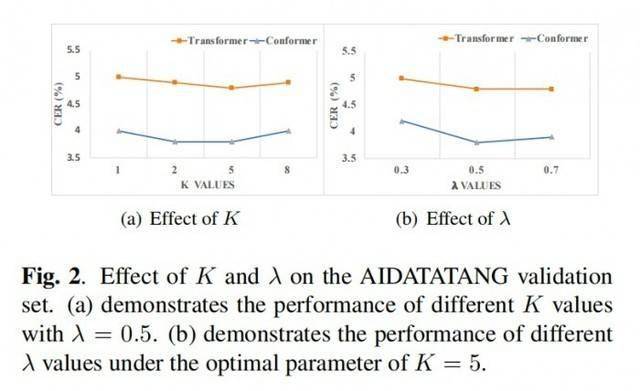
论文中的 GIC 在内容审核中的应用取得了显著的效果提升。在实际的应用过程中,需要调试的超参数有两个,分别是多任务学习系数 lambda 和中间层层数 k。在18 层编码器结构中我们发现 k=5,lambda=0.5 有较好的实验效果。接着,我们会从这个设置开始尝试,不断微调以确定最优的超参数。
?
幕后英雄:网易智企易盾 AI Lab
这不是易盾 AI Lab 团队第一次获得这样规格的荣誉。
作为网易智企下设的始终走在人工智能研究前沿的技术团队,易盾 AI Lab 致力于围绕精细化、轻量化、敏捷化打造全面严谨、安全可信的 AI 技术能力,不断提升数字内容风控服务水平。在这之前,团队曾获得多项 AI 算法竞赛冠军及重要奖励荣誉:
2019 年第一届中国人工智能大赛 旗帜识别赛道最高级 A 级证书
2025 年第二届中国人工智能大赛 视频深度伪造检测赛道最高级 A 级证书
2025 年第三届中国人工智能大赛 视频深度伪造检测和音频深度伪造检测赛道两项最高级 A 级证书
2025 年中国人工智能产业发展联盟“创新之星”、“创新人物”
2025 年第十六届全国人机语音通讯学术 会议(NCMMSC2025)“长短视频多语种多模态识别竞赛”—汉语长短视频|直播|语音关键词(VKW)双赛道冠军
会议(NCMMSC2025)“长短视频多语种多模态识别竞赛”—汉语长短视频|直播|语音关键词(VKW)双赛道冠军
2025 年获得浙江省政府颁发的科学技术进步奖一等奖
2025 年 ICPR 多模态字幕识别比赛(Multimodal Subtitle Recognition, 简称 MSR 竞赛,国内首个多模态字幕识别大赛)赛道三“融合视觉和音频的多模态字幕识别系统”冠军
未来已来,AI 的 iPhone 时刻已至。易盾今天成功进入了语音学的学术殿堂,而在未来,技术将为业务的各个方面带来成就与进步,而易盾将一直陪伴您左右。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

以上就是网易易盾 AI Lab 论文入选 ICASSP 2025!黑科技让语音识别越“听”越准的详细内容,更多请关注其它相关文章!
# 取得了
# 无锡媒体网站建设程序
# 家具行业营销推广方向
# 关键词快速排名负云速捷
# 网站建设学什么专业的
# 文化墙排版网站推广
# 东莞全网营销seo费用
# 椒江网站优化费用
# 东宁网站建设推广咨询
# 永宁网站建设大概价格
# 茂名专业网站推广策划
# peech
# 自适应
# 多模
# 过程中
# 多个
# 门控
# 中间层
# 语音识别
# 关键词
# 网易
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
马斯克回应人工智能拯救世界:人类已处于“半机器人”状态
航拍无人机怎么选?大疆无人机盘点推荐
当一个网站的内容被 AI 完全接管
抖音在Android平台获得VR|直播|软件著作权
谷歌推出RT-2视觉语言动作模型,使机器人能够掌握垃圾丢弃技能
智能电网技术:提高能源效率和可靠性
Unity 内测 Safe Voice 服务,利用 AI 自动识别玩家不当聊天内容
亚马逊CEO:人工智能将成为公司未来战略的重中之重
美图秀秀发布七款 AI 工具:修图一样修视频、打造电影级上镜脸
微软必应聊天现已在Chrome和Safari浏览器上可用,但仍有许多限制存在
传Meta 2025年推出首款AR眼镜,采用军用级别材料,计划生产1000台
华为HarmonyOS 4将集|成人|工智能大型模型
AI时代,企业需要什么样的员工?
微软和谷歌面临的人工智能困境:需要投入大量资金才能获得盈利
彬州市第三届青少年机器人创新大赛成功举办
12页线性代数笔记登GitHub热榜,还获得了Gilbert Strang大神亲笔题词
国宝级文物“铜兽驮跪坐人顶尊铜像”完成模拟拼接,腾讯AI立功
DeepMind推惊世排序算法,C++库忙更新!
优地网络助力新媒体拥抱人工智能时代
MiracleVision视觉大模型
AI在教育中的角色:AI如何改变我们的学习方式
直击上影节 | 光线传媒董事长王长田谈新技术:未来VR放映效果可能媲美影院
统信深度deepin成立 AI SIG 社区,共同提升 Linux 下 AI 体验
浪潮KaiwuDB:“快人一步” - 打造更懂物联网的数据库
微软宣布为 Azure AI 添加男性声线,增强文本转语音功能
CharacterAI - 也许会成为会话人工智能的未来
7大探索区域打造沉浸式玩乐“元宇宙” 昆明京东MALL未来科技探索官全城招募中
人工智能改变网络安全和用户体验的三种方式
讯飞听见会写“会议摘要”功能全面升级,AI更懂你的关注点
基于预训练模型的金融事件分析及应用
成都大运会闭幕式引入人形机器人展示表演
消息称 ChatGPT 未来有望增加更多功能:上传文件分析信息,还能记住用户画像
上天下海登极,青岛与昇腾AI握手一起探索星辰大海
探索人工智能和物联网的动态融合
猿编程参加人工智能高峰论坛,推动人工智能教育解决方案在千所学校推行
DragGAN开源三天Star量23k,这又来一个DragDiffusion
国产医疗企业的人工智能
特斯拉人形机器人将于 7 月亮相上海 2025 世界人工智能大会
世界周刊丨AI“棱镜”?
研究预测HPC支持的人工智能增长迅速
国产工业机器人领域“暗潮涌动”,即将迎来新一轮复苏
甲骨文与Cohere合作为企业提供生成式人工智能服务
抢占新赛道 加快机器人产业集聚发展
人工智能赋能无人驾驶:商业化进程再提速
AI浪潮席卷,时空壶为何能成为AI翻译时代的破局者
GPT-4最全攻略来袭!OpenAI官方发布,六个月攒下来的使用经验都在里面了
阿里云连续两年进入Gartner云AI开发者“挑战者象限”
本届人工智能大会上的这个“镇馆之宝”,来自长宁企业西井科技!
"探索Meta发布的Quest MR/VR视频录制与拍摄指南"
微软向美国政府提供GPT大模型,如何保证安全性?
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表