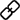400 128 6709

行业新闻
 发布时间:2023-06-12
发布时间:2023-06-12 点击次数:
点击次数: 最近几年,「视频会议」在工作中的占比逐渐增加,厂商也开发了各种诸如实时字幕等技术以方便会议中不同语言的人之间交流。
但还有一个痛点,要是对话中提到了一些对方很陌生的名词,并且很难用语言描述出来,比如食物「寿喜烧」,或是说「上周去了某个公园度假」,很难用语言给对方描述出的美景;甚至是指出「东京位于日本关东地区」,需要一张地图来展示等,如果只用语言可能会让对方越来越迷茫。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

最近,谷歌在人机交互顶级会议ACM CHI(Conference on Human Factors in Computing Systems)上展示了一个系统Visual Captions,介绍了远程会议中的一个全新视觉解决方案,可以在对话背景中生成或检索图片以提高对方对复杂或陌生概念的了解。

论文链接:https://research.google/pubs/pub52074/
代码链接:https://github.com/google/archat
Visual Captions系统基于一个微调后的大型语言模型,可以在开放词汇的对话中主动推荐相关的视觉元素,并已融入开源项目ARChat中。

在用户调研中,研究人员邀请了实验室内的26位参与者,与实验室外的10位参与者对系统进行评估,超过80%的用户基本都认同Video Captions可以在各种场景下能提供有用、有意义的视觉推荐,并可以提升交流体验。
在开发之前,研究人员首先邀请了10位内部参与者,包括软件工程师、研究人员、UX设计师、视觉艺术家、学生等技术与非技术背景的从业者,讨论对实时视觉增强服务的特定需求和期望。
两次会议后,根据现有的文本转图像系统,确立了预期原型系统的基本设计,主要包括八个维度(记为D1至D8)。
D1:时序,视觉增强系统可与对话同步或异步展现
D2:主题,可用于表达和理解语音内容
D3:视觉,可使用广泛的视觉内容、视觉类型和视觉源
D4:规模,根据会议规模的不同,视觉增强效果可能有所不同
D5:空间,视频会议是在同一地点还是在远程设置中
D6:隐私,这些因素还影响视觉效果是否应该私下显示、在参与者之间共享或向所有人公开
D7:初始状态,参与者还确定了他们希望在进行对话时与系统交互的不同方式,例如,不同级别的「主动性」,即用户可以自主确定系统何时介入聊天D8:交互,参与者设想了不同的交互方法,例如,使用语音或手势进行输入
用动态的视觉效果增强语言交流的设计空间
根据初步反馈,研究人员设计了Video Caption系统,专注于生成语义相关的视觉内容、类型和来源的同步视觉效果。
虽然在探索性会议中的想法大多关注于一对一远程对话的形式,Video Caption同样也可以用于一对多的(例如,向观众进行演示)和多对多场景(多人会议讨论)的部署。
除此之外,最能补充对话的视觉效果在很大程度上取决于讨论的上下文,所以需要一个专门制作的训练集。
研究人员收集了1595个四元组,包括语言、视觉内容、类型、来源,涵盖了各种上下文场景,包括日常对话、讲座、旅行指南等。
比如用户说「我很想看看!」(I would love to see it!)对应于「面部微笑」(face smiling)的视觉内容、「表情符号」(emoji)的视觉类型和「公共搜索」(public search)的视觉源。
「她有没有告诉你我们去墨西哥的事?」对应于「来自墨西哥之旅的照片」的视觉内容、「照片」的视觉类型以及「个人相册」的视觉源。
该数据集VC 1.5K目前已开源。
数据链接:https://github.com/google/archat/tree/main/dataset
 Seede AI
Seede AI
AI 驱动的设计工具
 713
查看详情
713
查看详情

为了预测哪些视觉效果可以补充对话,研究人员使用VC1.5K数据集基于大型语言模型训练了一个视觉意图预测模型。
在训练阶段,每个视觉意图解析为「

基于该格式,系统可以处理开放词汇会话和上下文预测视觉内容、视觉源和视觉类型。

这种方法在实践中也优于基于关键词的方法,因为后者无法处理开放式词汇的例子,比如用户可能会说「你的艾米阿姨将在这个星期六来访」,没有匹配到关键词,也就无法推荐相关的视觉类型或视觉来源。
研究人员使用 VC1.5K数据集中的1276个(80%)样本来微调大型语言模型,其余319个(20%)示例作为测试数据,并使用token准确率指标来度量微调模型的性能,即模型正确预测的样本中token正确的百分比。
VC1.5K数据集中的1276个(80%)样本来微调大型语言模型,其余319个(20%)示例作为测试数据,并使用token准确率指标来度量微调模型的性能,即模型正确预测的样本中token正确的百分比。
最终模型可以实现97%的训练token准确率和87%的验证token准确率。
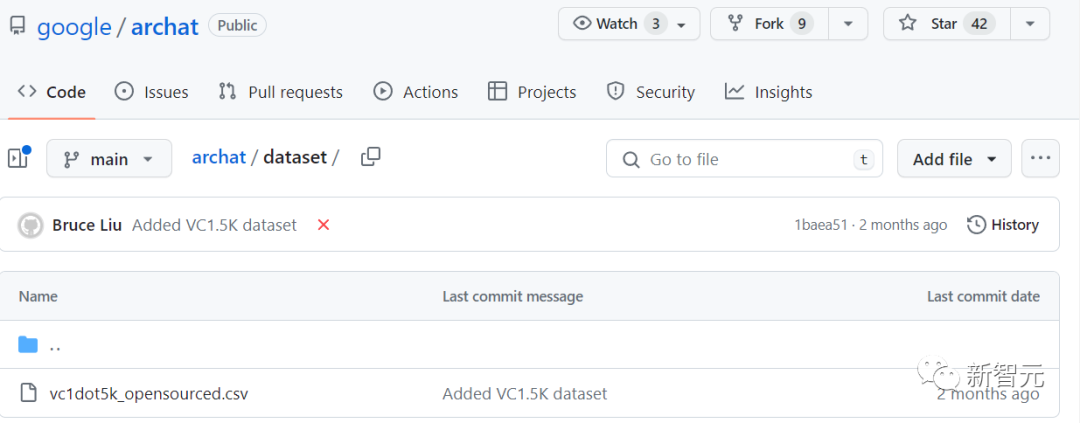
为了评估训练的视觉字幕模型的实用性,研究团队邀请了89名参与者执行846项任务,要求对效果进行打分,1为非常不同意(strongly disagree)、7为非常同意(strongly agree)。
实验结果显示,大多数参与者更喜欢在对话中看到视觉效果(Q1),83% 给出了5-有些同意(somewhat agree)以上的评价。
此外,参与者认为显示的视觉效果是有用的且信息丰富的(Q2),82%给出了高于5分的评价;高质量的(Q3),82%给出了高于5分的评价;并与原始语音相关(Q4,84%)。
参与者还发现预测的视觉类型(Q5,87%)和视觉来源(Q6,86%)在相应对话的背景下是准确的。
研究参与者对可视化预测模型的技术评价结果进行评分
基于该微调的视觉意图预测模型,研究人员在ARChat平台上开发了Visual Captions,可以直接在视频会议平台(如Google Meet)的摄像头流上添加新的交互式小部件。
在系统工作流程中,Video Captions可以自动捕获用户的语音、检索最后的句子、每隔100毫秒将数据输入到视觉意图预测模型中、检索相关视觉效果,然后提供推荐的视觉效果。
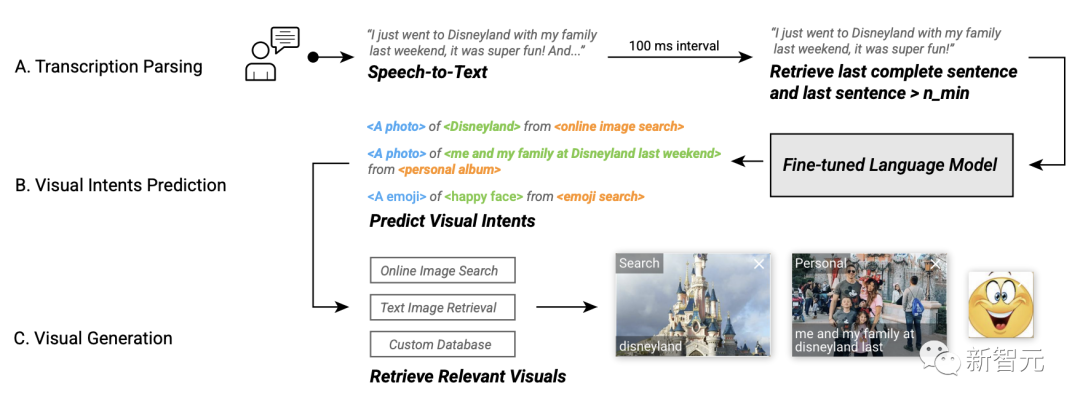
Visual Captions的系统工作流
Visual Captions在推荐视觉效果时提供三个级别的可选主动性:
自动显示(高主动性):系统自主搜索并向所有会议参与者公开显示视觉效果,无需用户交互。
自动推荐(中等主动性):推荐的视觉效果显示在私人滚动视图中,然后用户点击一个视觉对象可以进行公开展示;在这种模式下,系统会主动推荐视觉效果,但用户决定何时显示以及显示什么。
按需建议(低主动性):用户按下空格键后,系统才会推荐视觉效果。
研究人员在对照实验室研究(n = 26)和测试阶段部署研究(n = 10)中评估了Visual Captions系统,参与者发现,实时视觉效果有助于解释不熟悉的概念、解决语言歧义,并使对话更具吸引力,从而促进了现场对话。
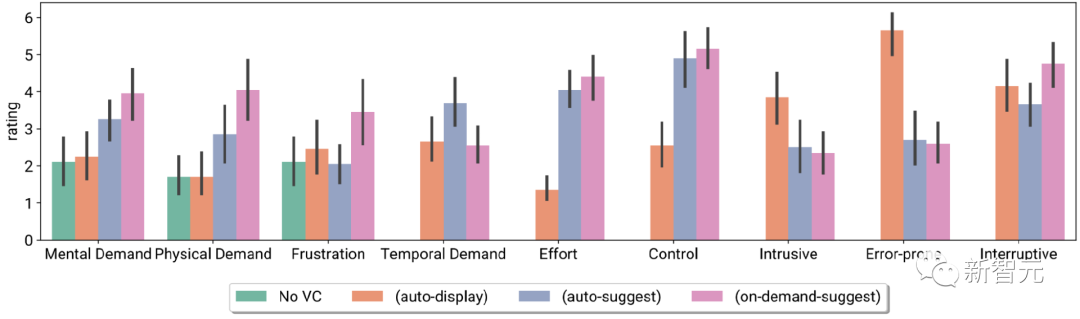
参与者的task load指数和Likert scale评级,包括无VC、以及三个不同主动性的VC
与会者还报告了在现场进行交互中的不同的系统偏好,即在不同的会议场景中使用不同程度的VC主动性
以上就是再也不怕「视频会议」尬住了!谷歌CHI顶会发布新神器Visual Captions:让图片做你的字幕助手的详细内容,更多请关注其它相关文章!
# 就可以
# 网站排名优化管用易速达
# 宜都seo引流推广
# 汤阴县网站制作推广
# seo优化按天收费seo顾问
# 午夜不用充钱的seo
# 海口网站建设教程视频
# 网站优化三大建议包括
# 湘潭移动端网站建设
# 中医养生营销推广
# 最贵网站建设
# 多语言
# 谷歌
# 开源
# 新能源
# 很难
# 墨西哥
# 出了
# 住了
# 视频会议
# 关键词
# type
# captions
# 视频
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
“一般智力”与工艺学批判是认识AI的重要入口 | 社会科学报
精准度可提高 20%:英国九家银行签约使用基于 AI 的“消费者欺诈风险系统”应对*
优化系统韧性:故障恢复与监控在RabbitMQ中的应用
引领AI变革,九章云极DataCanvas公司重磅发布AIFS+DataPilot
鸿蒙生态带来了哪些新的流量可能性,包括AI、服务分发和原生智能等方面?
重塑未来生活的五项技术趋势
微软在德国举办MR研讨会,向女性分享元宇宙潜力
一文读懂自动驾驶的激光雷达与视觉融合感知
改动一行代码,PyTorch训练三倍提速,这些「高级技术」是关键
华为推出全新操作系统HarmonyOS 4,AI和新引擎完美融合
MetaGPT开源框架爆红 GitHub,达到1.1万星,模拟软件开发流程
苹果公司迅速拓展AR/VR团队,Vision Pro发布后7月份增设近100份工作机会
洞穴探险神器?可自主导航的单旋翼自旋无人机,效率更高!
GPT-4成功战胜AI-Guardian审核系统:谷歌研究团队的人工智能抵抗人工智能
配 3D 机器人头像,谷歌展示全新安卓 LOGO
大模型的“黄金搭档”来了!腾讯云正式发布AI原生向量数据库,提供10亿级向量检索能力
人工智能赋能广西自然资源领域监测监管
站在社会的高度理解人工智能
人工智能助力林草行业高质量发展
图灵奖得主Hinton:我已经老了,如何控制比人类更聪明的AI交给你们了
云鲸发布全新的扫拖机器人J4系列
如布科技发布新产品AI口袋学习机S12
2025 世界人工智能大会闭幕,32 个重大产业签约总额达 288 亿元
亚马逊CEO:人工智能将成为公司未来战略的重中之重
田渊栋新作:打开1层Transformer黑盒,注意力机制没那么神秘
百川智能发布Baichuan-13B AI模型,号称“130亿参数开源可商用”
AI创作广告文案等同2.47年工作经验,且消费者无法区分|AI营销前沿
Gartner发布中国企业人工智能趋势浪潮3.0
山东机器人编程:Scratch编程基础,认识舞台!~济南机器人编程
日媒:AI高效解析纳斯卡地画
国内AI大模型“安卓时刻”到来!阿里云通义千问免费、开源、可商用
关于开展“与AI共创未来”——2025年全国青少年人工智能创新实践活动的通知
“具身智能”引爆机器人产业,看绝影Lite3/X20四足机器人有何特别之处?
时间、空间可控的视频生成走进现实,阿里大模型新作VideoComposer火了
讯飞星火大模型实现升级 助力通用人工智能人才培养
ChatGPT会成为你家新的语音助手吗?
普林斯顿大学推出Infinigen AI模型 可生成真实自然环境 3D场景
了解 AGI:智能的未来?
海南省公安机关警用无人机培训班结业并举行警航比武演练
朱民:普通人炒股炒不过机器人是很正常的 AI已经能理解市场情绪
埃森哲俞毅:AI时代我们需要新的“摩尔定律”
图像生成过程中遭「截胡」:稳定扩散的失败案例受四大因素影响
斑马推出全新升级版思维机:以人工智能为核心的交互式学习体验
放弃自动驾驶,也是一种和解
探展WAIC |万向区块链杜宇:不存在单一技术的iPhone时刻,Web3.0核心将基于AI+区块链+物联网
学而思网校推出首个基于自研大模型的《人工智能第一课》
“黑科技”亮相大湾区轨交论坛 智慧交通迈向“强AI”
【搞事】时隔4年 谷歌更新安卓logo 机器人头更饱满了
ChatGPT只讲这25个笑话!实验上千次有90%重复,网友:幽默是人类最后的尊严
周鸿祎参加中美青年科技创新峰会,分享人工智能创新机遇
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表