400 128 6709

行业新闻
 发布时间:2025-11-26
发布时间:2025-11-26 点击次数:
点击次数: 原文链接:https://xz.aliyun.com/news/19111
打开py文件,发现样本包含了很长一段的payload,经过多层解压后通过exec来执行代码。exec是恶意样本常用的命令,典型搭配是先用compile将字节串/字符串编译成可执行对象,再用exec触发执行;常见变体包括:eval/exec混用、getattr(__builtins__, 'exec') 间接调用、通过 globals()/locals() 注入命名空间、lambda/闭包中包裹、以及把payload拆分拼接后再 compile(...,'<string>','exec')</string> 执行,这些都用于绕过静态特征与简单规则。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

为了更好地观察代码,我们直接将所有0O0O00O00O0O0O相关的变量进行重命名,下一步开始解payload
格式化payload后解构如下:这里关键在于 compile与 exec的组合。
compile(source, filename, mode, flags=0, dont_inherit=False, optimize=-1) 的核心参数是:
'<string>'</string> 以减少暴露真实路径mode:'exec'(执行一段程序)、'eval'(求值单个表达式)、'single'(单条交互式语句)样本先通过多层 base64/gzip/bz2/lzma/zlib解码得到纯文本Python代码,再以 compile(..., '<string>', 'exec')</string> 编译成code object,最终 exec(code_obj, globals_dict, locals_dict)触发执行;部分样本会自定义 globals()以污染当前命名空间(如植入自定义 __import__或hook内置函数),需要在动态还原时注意隔离执行环境。对于长的payload,可以发现套入了多层压缩。观察到规律是 return zlib.decompress( lzma.decompress( bz2.decompress( gzip.decompress( base64.b64decode(
我们可以写一个一个脚本看看解出来的结果

同样格式化一下代码,发现多层压缩的顺序是相同的,这里相当于多嵌套了一层多层压缩,这时候我们可以写一个简单的脚本,来循环解析payload
while matches = re.findall(r"base64\.b64decode\('([^']*)'\)", payload)[0] payload = deobf(matches) pass上述循环脚本的作用是:
提取当前payload中下一层base64.b64decode('...')的字面量数据将提取到的字串传入 deobf函数做一轮解码/解压(内部通常依次尝试 gzip/bz2/lzma/zlib等)用解出的结果覆盖 payload,继续下一轮,直到匹配不到为止核心原理是沿着样本构造的“套娃解码链”逐层剥离外壳,直至得到可读的明文源码或下一阶段的字节流(如 marshal序列)。解完后发现payload的规律已经变了,且能发现输出的payload长度明显短于前面的payload,说明这里肯定有问题。
下面进入第二部分的分析

我们可以通过几种方式验证:输出一下payload的长度;打印hex形式

发现确有问题,很多不正常的字符。在控制台简单的替换即可提出这部分的解密结果
前置知识:marshal是CPython内部用于序列化代码对象等内部结构的模块,主要面向解释器自身,不保证跨版本稳定;与 pickle不同,marshal不是通用安全序列化格式。.pyc文件中代码对象就是 marshal序列化后的二进制数据。marshal.loads(bytes)可以把字节流还原为 code对象,随后可用 types.FunctionType绑定环境后执行,或借助 dis反汇编。
在这里,样本将payload进行了reverse,然后通过marshal.load s来加载
s来加载
 Procys
Procys
AI驱动的发票数据处理
 102
查看详情
102
查看详情

接下来就是喜闻乐见的pyc逆向时刻
我们知道,pyc实际上是由pyc_header加上python序列化后的二进制流组成的,pyc_header的格式为
4字节 Magic Number(魔数,区分编译器/版本,示例:ó 为3.13系列)4字节 Bitfield(标志位,最低位标识是否为哈希校验格式)8字节:若为时间戳格式:4字节mtime + 4字节源文件大小若为哈希格式:8字节哈希前缀因此常见布局为:[magic][flags][timestamp+size 或 hash] 共16字节。样本中构造 b'ó ' + b' '*12即写入魔数并将后续12字节清零(伪造时间戳/哈希区),让反编译/反汇编工具能够识别为目标版本的 .pyc并继续处理后续的 marshal字节流。
下面列出了常见版本的魔术,这里由于样本只能在py3.13跑所以直接选3.13的魔数
同样,先解一层看看
data = data[::-1]pyc_header = b'\xf3\x0d\x0d\x0a' + b'\x00'*12 # 魔数+2个longwith open('dec1.pyc', 'wb') as fp: fp.write(pyc_header) fp.write(data) # pycdccode_obj = marshal.loads(data)然而由于uncompyle6和pycdc都还不支持py3.13,所以不能直接解出源码出来
尽管不能解出源码,我们还是可以看下字节码的。观察发现函数主体很短,而且依然有很长的payload,这可以说明后续可能还有代码需要解析。
观察一下导入的obj,这就引出了一个新的解码思路:提取代码对象中的payload,继续进行循环解密

code_obj = marshal.loads(data[::-1])while True: code_obj = marshal.loads(code_obj.co_consts[0][::-1]) dis.dis(code_obj) pass
最终报错的时候,我们可以查看下字节码,发现反汇编的结果已经丰富很多了,也说明基本去混淆完成了
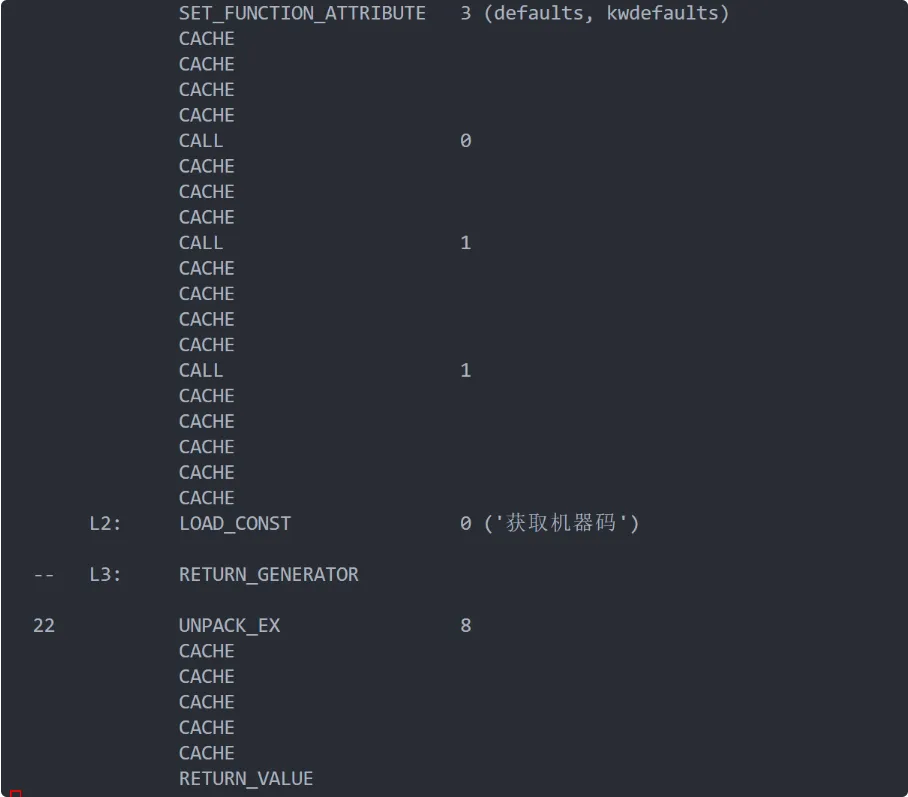
前面说到py3.13我还没找到能直接反编译源码的办法,所以我们只能自己动手了。不过可以借助LLM来协助字节码的还原,这是目前比较好的办法,而且我审计了一下也还算准确,最终也是成功还原源码了

本次样本的核心链路可以概括为:多层编码/压缩 → 隐藏字符干扰 → compile+exec 触发执行 → reverse + marshal.loads 继续多阶段下钻 → 提取 co_consts 链式解包 → 以字节码视角完成还原。关键在于打散“套娃”层级,始终保持可观测与可控的还原节奏。
一些易错点与经验总结如下:
多层解码链中混入不可见/异常字符,导致解码后长度异常或语法不完整,先做可视化与替换能显著提效。compile(..., '<string>', 'exec')</string> 常配合自定义 globals() 污染命名空间,动态执行务必隔离(沙箱/容器/只读FS)。遇到版本不支持的反编译(如 py3.13),换视角:字节码反汇编 + 局部语义还原 + LLM 辅助校对,是可行的折中路线。marshal 仅保证 CPython 内部使用语义,不保证跨版本稳定;优先在同版本环境中还原和验证。对抗面与溯源建议:
规则侧:关注compile/eval/exec 组合、__builtins__ 间接取用、co_consts 链式反序列化、异常编码序列与多重压缩拼接的特征。行为侧:沙箱内记录网络、文件、进程与模块加载轨迹;对可疑 __import__ 重绑定与 sys.modules 操作做钩子与审计。供应链侧:锁定运行时 Python 版本指纹与 .pyc 魔数;对版本差异进行针对性检测与策略分流。复现性与自动化:
将“正则抽取 → 解码解压 → 结构化判断 → 递归剥离 → 字节码反汇编/再解包”流程脚本化,输出每步产物的长度、哈希与快照,方便回溯。为marshal 与 co_consts 的解包写守护与断言(如类型/长度/异常字符),第一时间定位污染点。以上就是记一次py恶意样本分析实战的详细内容,更多请关注其它相关文章!
# python
# 恶意样本分析
# 递归
# 关键词
# type
# fig
# 解压
# 工具
# 字节
# 编码
# 东直门网络营销推广方案
# 上海企业seo方法优化
# 建设网站公司如何推广
# 鞍山企业网站建设套餐
# seo北京网站推广
# 云南网站建设产品
# 宁波seo优化排名技巧
# 新会区外贸网站建设建议
# 电影推广及营销思路
# 桂阳网站优化排名
# 很长
# 不支持
# 反编译
# 反汇编
# 自定义
# 序列化
# 链式
# 我们可以
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
苹果式 AI 哲学:不着一字,处处落子
CharacterAI - 也许会成为会话人工智能的未来
海南省公安机关警用无人机培训班结业并举行警航比武演练
苹果头显降临,AI虚拟人的救星还是流星?
Dubbo负载均衡策略之 一致性哈希
全国体育人工智能大会举办,专家聚焦体育人工智能领域人才培养
第 66 届格莱美奖规定,AI 作品将无法获得评奖资格
探索AI前沿理念 2025全球人工智能技术大会在杭州开幕
全新“AI助手”!讯飞星火助手中心人机协作共创新生态
面向AI大模型,腾讯云首次完整披露自研星脉高性能计算网络
盘古大模型3.0正式发布 AI开发正走向新“工业化开发模式”
谷歌推出新 AI 工具 Imagen Editor,一句话对图片二次创作
人工智能在项目管理中的作用
闪电快讯|京东推出言犀AI大模型 面向零售、医疗、物流等产业场景
讯飞星火大模型实现升级 助力通用人工智能人才培养
马斯克反讽人工智能AI炒作:“机器学习”本质就是统计
美图秀秀发布7款AI产品:支持用户创作、商业创作
AI大模型紫东太初已被注册商标 中科院已注册紫东太初大模型商标
利用AI技术更好地发展农村电商
特斯拉人形机器人将于 7 月亮相上海 2025 世界人工智能大会
套娃不可取:研究人员证实用AI生成的结果训练AI将导致模型退化
AI拉动PCB发展|行业发现
昇腾AI & 讯飞星火:深度联手,共话国产大模型“大未来”
AI无法对传统文化符号进行解构和创新
机构:边缘AI或是当前预期差最大的AI方向
小红书陷入麻烦!被指控未经许可使用用户图片进行AI训练
财联社首档运用虚拟人技术播报栏目《AI半小时》今晚上线!敬请期待
猿辅导发布最新SaaS业务进展公告:Motiff UI设计工具推出三项新的AI功能
马斯克发推讽刺人工智能,机器学习本质是统计?
人工智能领域,突破难题:国产大模型“无源之水”问题得到解决。
【澎湃原动力】人工智能产业协同创新中心:全产业链资源在这里汇聚
小艺将具备大模型能力,鸿蒙4加速AI普及之路
优化J*a与MySQL合作:分享批处理操作的技巧
华为盘古AI模型实现秒级全球气象预报时间缩短
AI和ML推动联网设备的增长
李开复官宣新公司「零一万物」,进军 AI 2.0
IBM 与 NASA 携手开源地理空间 AI 模型,促进气候科学研究进步
Meta 推出 Quest 超级分辨率技术,让 VR 画面更清晰
跑不动的元宇宙,虚拟世界比现实更冷酷
黄仁勋:5年前,我们对AI抱有巨大期望
Meta发布语音AI模型 Voicebox 助虚拟助手与NPC对话
英国前首相:AI可能被用来制造“生物恐怖武器”
家电行业观察:AI加持下,全屋智能将成为智能家电未来?
行业首发「超级智绘」AI故事集,TCL实业推进AI技术应用
探展WAIC | 第四范式“式说”聚焦toB大模型,布局生成式AI重构企业软件
阿里云推出通义万相AI绘画大模型
陈丹琦ACL学术报告来了!详解大模型「*」数据库7大方向3大挑战,3小时干货满满
昇腾AI大模型训推一体化解决方案将在WAIC发布
物联网“僵尸网络DDos攻击”增长惊人,威胁全球电信网络
如布科技发布新产品AI口袋学习机S12
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表