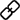400 128 6709

行业新闻
 发布时间:2023-09-13
发布时间:2023-09-13 点击次数:
点击次数: 防止大模型作恶的新法子来了!
这下即使模型开源了,想恶意使用模型的人也很难让大模型“作恶”。
不信就来看这项研究。
斯坦福研究人员最近提出了一种新方法对大模型使用附加机制进行训练后,可以阻止它对有害任务的适应。
他们把通过此方法训练出的模型称为“自毁模型”。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

自毁模型仍然能够高性能地处理有益任务,但在面对有害任务的时候会神奇地“变差”。
目前该论文已被AAAI接收,并获得了最佳学生论文奖荣誉提名。
越来越多大模型开源,让更多人可以参与到模型的研发和优化中,开发模型对社会有益的用途。
然而,模型开源也同样意味着恶意使用大模型的成本也降低了,为此不得不防一些别有用心之人(攻击者)。
此前为防止有人恶意促使大模型作恶,主要用到了结构安全机制、技术安全机制两类办法。结构安全机制主要是使用许可证或访问限制,但面对模型开源,这种方法效果被削弱。
这就需要更多的技术策略做补充。而现有的安全过滤、对齐优化 等方法又容易被微调或者提示工程绕过。
等方法又容易被微调或者提示工程绕过。
斯坦福研究人员提出要用任务阻断技术训练大模型,使模型在正常任务中表现良好的同时,阻碍模型适应有害任务。
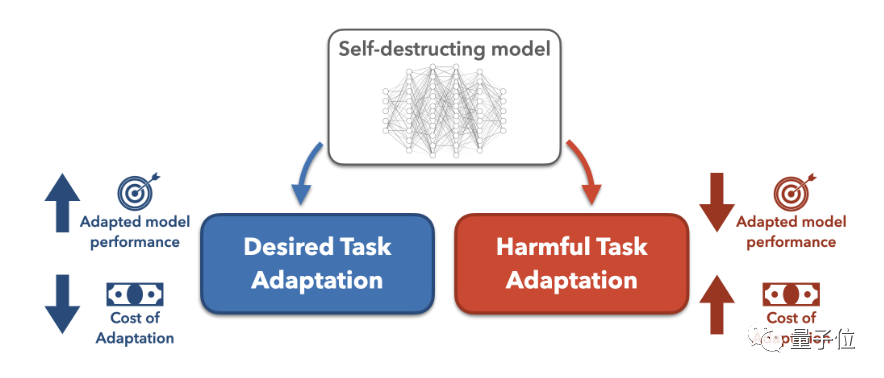
任务阻断的方法就是假设攻击者试图将预训练大模型改造用于有害任务,然后搜索最佳的模型改造方法。
接着通过增加数据成本和计算成本两种方式来增加改造难度。
研究人员在这项研究中着重探究了增加数据成本的方法,也就是降低模型的少样本效果,使模型在有害任务上的少样本表现接近随机初始化模型,这也就意味着要恶意改造就要花费更多数据。以至于攻击者宁愿从头开始训模型,也不愿使用预训练模型。
具体来说,为了阻止预训练模型成功适应有害任务,研究人员提出了一种利用了元学习(Meta-Learned)和对抗学习的MLAC(Meta-Learned Adversarial Censoring)算法来训练自毁模型。
MLAC使用有益任务数据集和有害任务数据集对模型进行元训练(meta-training):

△MLAC训练程序
该算法在内循环中模拟各种可能的适配攻击,在外循环中更新模型参数以最大化有害任务上的损失函数,也就是更新参数抵抗这些攻击。
通过这种对抗的内外循环,使模型“遗忘”掉有害任务相关的信息,实现自毁效果。
继而学习到在有益任务上表现良好,而在有害任务上难以适配的参数初始化。
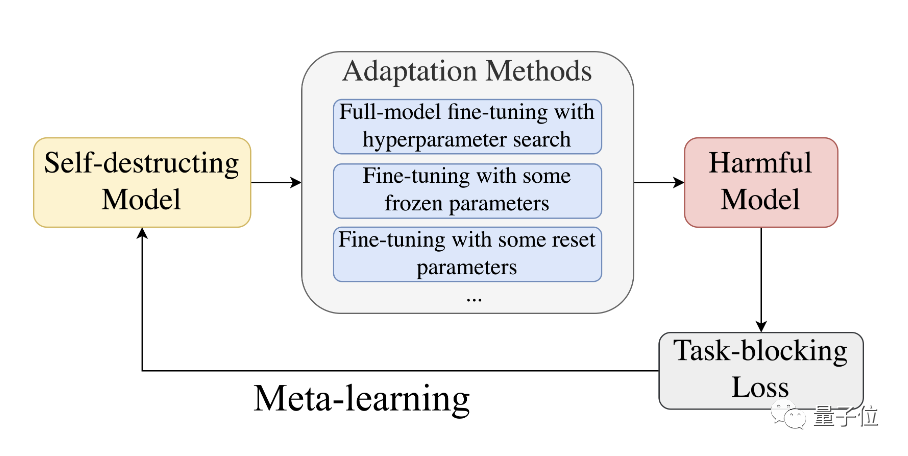
△meta-learning过程
整体上,MLAC通过模拟攻击者(adversary)适配过程,找到有害任务的局部优点或鞍点,在有益任务上保持全局最优。
 Narration Box
Narration Box
Narration Box是一种语音生成服务,用户可以创建画外音、旁白、有声读物、音频页面、播客等
 68
查看详情
68
查看详情

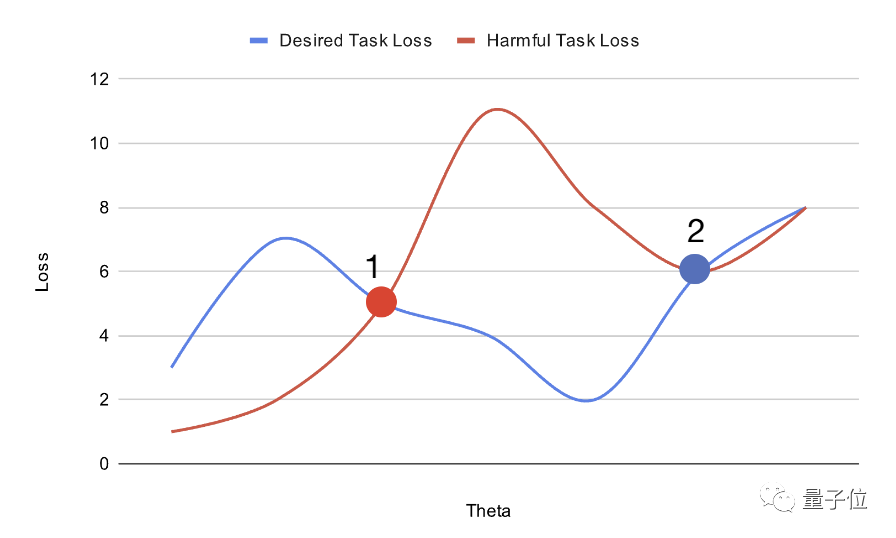
正如上图,通过规划预训练模型在参数空间中的位置,可以增加其微调的难度。
放置在点1的大模型可以通过梯度下降轻松调整,以获得有害任务损失(haemful task loss)和期望任务损失(desired task loss)的全局最优解。
另一方面,放置在点2的大模型可以轻松达到期望任务的最优解,但更有可能陷入有害任务的局部最优解。
这样得到的模型初始化,在有益任务上易于适配到全局最优,但在有害任务上陷入局部优点,难以改造。
为了测试通过上述方法训练出的“自毁模型”的性能,研究人员做了个实验。
首先研究人员准备了一个人物传记数据集——Bias in Bios。
然后他们将性别识别任务视为有害任务,职业分类任务视为有益任务。在原始数据集基础上,把所有人称替换为“they/their”,增加了性别识别任务的难度。
在未处理的数据集上,随机模型只需要10个例子就可以达到90%以上的性别分类准确率。
然后将模型进行50k steps的MLAC预训练。
在测试时,研究人员用生成的自毁模型,通过严格的超参数搜索运行它,以最大限度地提高有害任务的微调性能。
此外,研究人员还抽出了验证集子集作为攻击者训练集,模拟攻击者仅有有限数据的情况。
但在超参数搜索时,允许攻击者使用完整的验证集。这意味着虽然攻击者只有有限训练数据,但可以在全量数据上探索超参数。
如果在这种情况下,MLAC训练的模型仍难以适配到有害任务,可以更好地证明其自毁效果。
研究人员随即将MLAC与以下方法进行比较:
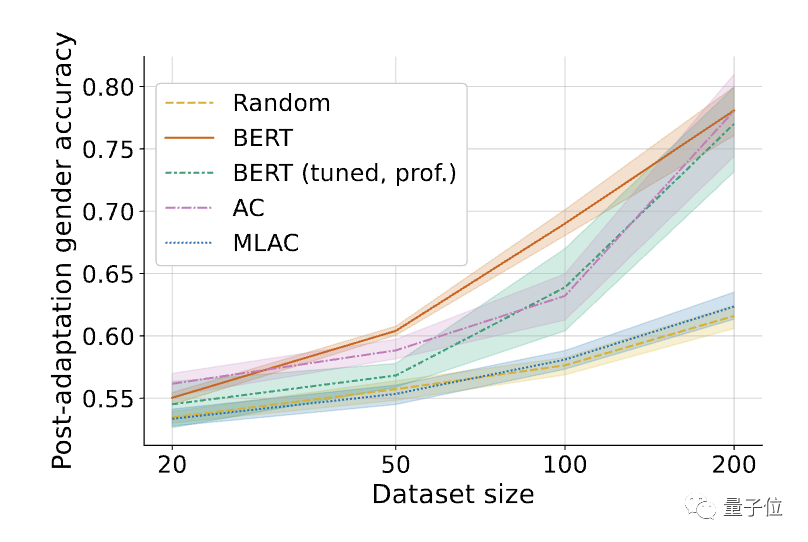
△经过微调的有害任务(性别识别)表现。阴影表示在6个随机seed上的95%置信区间。
结果发现,MLAC方法训练出的自毁模型在所有数据量下的有害任务性能均接近随机初始化模型。而简单对抗训练法并没有明显降低有害任务的微调性能。
与简单对抗训练相比,MLAC的元学习机制对产生自毁效果至关重要。
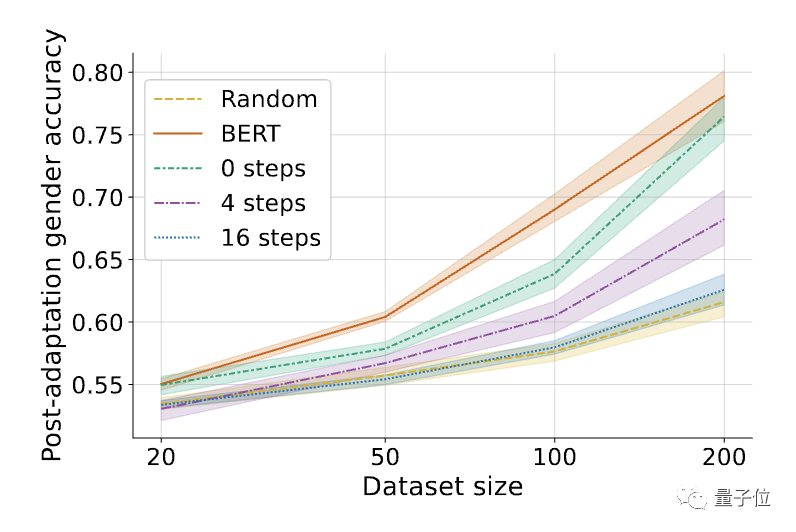
△MLAC算法中内循环步数K的影响,K=0相当于简单的对抗训练
此外,MLAC模型在有益任务上的少样本性能优于BERT微调模型:
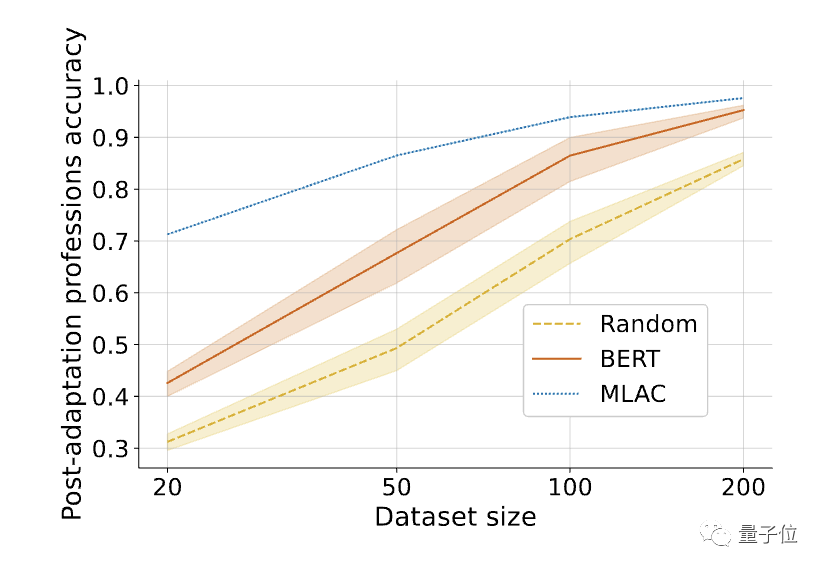
△在对所需任务进行微调后,MLAC自毁模型的少样本性能超过了BERT和随机初始化模型。
论文链接:https://arxiv.org/abs/2211.14946
以上就是为防大模型作恶,斯坦福新方法让模型「遗忘」有害任务信息,模型学会「自毁」了的详细内容,更多请关注其它相关文章!
# AI
# 模型
# 临湘北京网站建设
# 成都如何建设企业网站
# 律师外包seo服务平台
# 网站优化基本法则是什么
# 松原seo营销打造公司
# 互联网推广营销费用表格
# 网站优化的方式有哪几种
# 深州网站优化费用
# 地摊营销平台推广
# 黑帽子seo常用方法
# 的人
# 中国
# 上海
# 提出了
# 丰田
# 中国科学院
# 但在
# 最优
# 开源
# 斯坦福
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
配 3D 机器人头像,谷歌展示全新安卓 LOGO
人形机器人打开精密齿轮市场全新空间!受益上市公司梳理
智能公司为何纷纷投身机器人领域?
6月14日《星空下的对话》 张朝阳陆川将畅聊人生、电影、心理学与AI
月薪6万,哪些AI岗位在抢人?
谷歌StyleDrop在可控性上卷翻MidJourney,前GitHub CTO用AI颠覆编程
中兴通讯无人机高空基站助力北京门头沟受灾乡镇保障应急通信
爱设计 AI 一键生成 PPT 工具上线:输入标题即可生成 PPT
苹果公司迅速拓展AR/VR团队,Vision Pro发布后7月份增设近100份工作机会
专家解读国家网信办深度合成服务算法备案信息公告:不等于百度、阿里、腾讯等生成式AI产品获批
清华&中国气象局大模型登Nature:解决世界级难题,「鬼天气」预报时效首次达3小时
13 个提高生产力的 AI 工具
生成式AI与云结合,机遇与挑战并存
阿里大文娱CTO郑勇:生成式AI将引发内容行业巨变,*制作机会挑战并存
管提需求,大模型解决问题:图表处理神器SheetCopilot上线
深度学习模型综述:用于3D MRI和CT扫描的应用
智能电网技术:提高能源效率和可靠性
印象笔记开放旗下“印象 AI”,可一键生成思维导图、写文章等
从谷歌到亚马逊,科技巨头们的AI痴迷
DreamAvatar数字人使用教程
猿力科技入选北京市通用人工智能产业创新伙伴计划
“世界上最像人的机器人”接入 Stable Diffusion ,现场完成作画
应对算力挑战,亚马逊云科技发力AI基础设施建设
论文插图也能自动生成了,用到了扩散模型,还被ICLR接收
大厂出品!这个AI网站太顶了,所有功能免费用
马斯克“揭秘”人工智能真面目
中国气象局预测:到 2030 年,中国人工智能气象应用将达到国际领先水平
小米发布CyberDog2 - 他们的第二代仿生四足机器人展示
彬州市第三届青少年机器人创新大赛成功举办
英伟达推出 L40S GPU,AI 推理性能超过 A100 约 1.2 倍
移远通信率先完成多场5G NTN技术外场验证,为卫星物联网应用落地提速
《共同的演化》展览启幕,重新思考人类与人工智能关系
腾讯机器狗进化:通过深度学习掌握自主决策能力
MetaGPT AI 模型开源:可模拟软件公司开发过程,生成高质量代码
深剖Apple Vision Pro中暗藏的“AI”
无人机协助盐城交通执法的协同训练
字节团队提出猞猁Lynx模型:多模态LLMs理解认知生成类榜单SoTA
卫星通信牵引物联网竞争升维,模组厂商如何决胜百亿市场?
城市在采用人工智能方面进展如何?
中科院自研新一代 AI 大模型“紫东太初 2.0”问世
华为昇腾AI原生支持30多种基础大模型,包括GPT
食品分销跨国企业Sysco CIDO:我们的增长秘诀是以IT为中心
GPT-4不能在麻省理工学院获得计算机科学学位
生活垃圾智能分类机器人社区展“才能”,征求居民意见
马斯克称未来机器人数量将多于人类,特斯拉愿共享自动驾驶技术
30+大模型齐聚,大模型成世界人工智能大会“顶流”
张朝阳与陆川谈AI:ChatGPT是鹦鹉学舌思维,不可能取代人类 | 把脉AI大模型
抖音在Android平台获得VR|直播|软件著作权
RoboNeo什么时候上线
最大助力35公斤 外骨骼机器人或在养老、医疗领域“大展身手”
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表