400 128 6709

行业新闻
 发布时间:2025-08-01
发布时间:2025-08-01 点击次数:
点击次数: 该内容介绍轻量级文本识别创新大赛,围绕轻量级文字识别技术,提供12万张真实图片数据集。还讲解了基于PaddleOCR的环境设置、数据准备、训练参数配置、模型训练、评估、预测及基于预测引擎的预测等流程,包括模型大小限制及解决办法。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

近年来,深度学习技术在很多方向都取得了巨大的成功,尤其是计算机视觉领域,已经实现了广泛的落地和应用,但由于深度神经网络计算复杂度高,模型参数量大,限制了其在一些场景和设备上进行部署,特别是在移动嵌入式设备的部署。因此,对于模型大小的需求也变得越来越重要。
OCR文本识别任务作为计算机视觉领域的核心问题之一,旨在找出图像中所有的文字信息,进而确定它们的位置和内容。由于文字有不同的外观、形状、尺度和姿态,加上成像时的光照、遮挡等因素干扰,OCR文本识别一直是计算机视觉领域极具挑战性的问题之一,但是在现实世界中又具有庞大的应用基础。
本次挑战赛以 轻量级文字识别技术创新 为主题,提供大规模的中文场景文字识别数据,要求参赛选手兼顾准确率指标与模型大小,并重点考察选手的网络结构设计与训练调优能力。本次挑战赛旨在为研究者提供学术交流平台,进一步推动中文场景文字识别算法与技术的突破。
本次赛题数据集共包括12万张真实图片,其中10万张图片作为训练集,A榜,B榜各1万张图片作为测试集。 本次赛题数据集既有来自街景的图片(例如店铺标牌、地标等),也有来自文档、网图截取的图片。










PaddleOCR https://github.com/paddlepaddle/PaddleOCR 是一款全宇宙最强的用的OCR工具库,开箱即用,速度杠杠的。
In [ ]# 从gitee上下载PaddleOCR代码,也可以从GitHub链接下载!git clone https://gitee.com/paddlepaddle/PaddleOCR.git# 升级pip!pip install -U pip # 安装依赖%cd ~/PaddleOCR %pip install -r requirements.txtIn [12]
%cd ~/PaddleOCR/ !tree -L 1
/home/aistudio/PaddleOCR . ├── benchmark ├── configs ├── deploy ├── doc ├── inference ├── __init__.py ├── LICENSE ├── log ├── MANIFEST.in ├── output ├── paddleocr.py ├── ppocr ├── PPOCRLabel ├── ppstructure ├── README_ch.md ├── README.md ├── requirements.txt ├── setup.py ├── StyleText ├── test_tipc ├── tools ├── train_rec.log └── train.sh 13 directories, 10 files
据悉train数据集共10万张,解压,并划分出10000张作为测试集。
# 解压缩数据集%cd ~ !unzip -qa data/data92473/A榜测试数据集.zip -d data/ !unzip -qa data/data92473/训练数据集.zip -d data/
/home/aistudioIn [ ]
# 使用命令查看训练数据文件夹下数据量是否是10万张!cd ~/data/训练数据集/TrainImages && ls -l | grep "^-" | wc -l
100000
# 读取数据列表文件import pandas as pd
%cd ~
data_label=pd.read_csv('data/训练数据集/LabelTrain.txt',sep='\t')
data_label.head()/home/aistudio
Train_000000.jpg 光环 0 Train_000001.jpg 主营:热干面 原汤面 1 Train_000002.jpg 创亿 2 Train_000003.jpg 810 3 Train_000004.jpg 香花桥社区(街道) 4 Train_000005.jpg 藍色经典In [ ]
# 对数据列表文件进行划分%cd ~/data/训练数据集/print(data_label.shape)
train=data_label[:90000]
val=data_label[89999:]
train.to_csv('train.txt',sep='\t',header=None,index=None)
val.to_csv('val.txt',sep='\t',header=None,index=None)/home/aistudio/data/训练数据集 (99999, 2)In [ ]
# 查看数量print(train.shape)print(val.shape)
(90000, 2) (10000, 2)In [ ]
!head ~/data/训练数据集/val.txt
Train_090000.jpg 运行时间 Train_090001.jpg 无座 Train_090002.jpg 中国进出口银行 Train_090003.jpg 被人抱紧 Train_090004.jpg 与 Train_090005.jpg 展开 Train_090006.jpg 金” Train_090007.jpg 欢迎光临 Train_090008.jpg 在2日内到有效 Train_090009.jpg 车服务公司In [ ]
!head ~/data/训练数据集/train.txt
Train_000001.jpg 主营:热干面 原汤面 Train_000002.jpg 创亿 Train_000003.jpg 810 Train_000004.jpg 香花桥社区(街道) Train_000005.jpg 藍色经典 Train_000006.jpg 承接:国内外针 梭织订单 欢迎来料加工 Train_000007.jpg PHOENIXTEA Train_000008.jpg 电话:13640839583 Train_000009.jpg B7 Train_000010.jpg 申滨路
以PaddleOCR/configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml为基准进行配置
使用CRNN算法,backbone是MobileNetV3,损失函数是CTCLoss
Architecture:
model_type: rec
algorithm: CRNN
Transform:
Backbone:
name: MobileNetV3
scale: 0.5
model_name: small
small_stride: [1, 2, 2, 2] Neck:
name: SequenceEncoder
encoder_type: rnn
hidden_size: 48
Head:
name: CTCHead
fc_decay: 0.00001对Train.data_dir, Train.label_file_list, Eval.data_dir, Eval.label_file_list进行配置
 Openflow
Openflow
一键极速绘图,赋能行业工作流
 88
查看详情
88
查看详情

Train: dataset: name: SimpleDataSet data_dir: /home/aistudio/data/训练数据集/TrainImages label_file_list: ["/home/aistudio/data/训练数据集/train.txt"] ... ...Eval: dataset: name: SimpleDataSet data_dir: /home/aistudio/data/训练数据集/TrainImages label_file_list: ["/home/aistudio/data/训练数据集/val.txt"]
use_gpu、cal_metric_during_train分别是GPU、评估开关
Global: use_gpu: false # true 使用GPU ..... cal_metric_during_train: False # true 打开评估
Train.loader.num_workers:4Eval.loader.num_workers: 4
Global:
use_gpu: true
epoch_num: 500
log_smooth_window: 20
print_batch_step: 10
s*e_model_dir: ./output/rec_chinese_lite_v2.0
s*e_epoch_step: 3
# evaluation is run every 5000 iterations after the 4000th iteration
eval_batch_step: [0, 200] cal_metric_during_train: True
pretrained_model:
checkpoints:
s*e_inference_dir:
use_visualdl: True
infer_img: doc/imgs_words/ch/word_1.jpg
# for data or label process
character_dict_path: ppocr/utils/ppocr_keys_v1.txt
max_text_length: 25
infer_mode: False
use_space_char: True
# 结果保存文件
s*e_res_path: ./output/rec/predicts_chinese_lite_v2.0.txtOptimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine
learning_rate: 0.001
warmup_epoch: 5
regularizer:
name: 'L2'
factor: 0.00001Architecture:
model_type: rec
algorithm: CRNN
Transform:
Backbone:
name: MobileNetV3
scale: 0.5
model_name: small
small_stride: [1, 2, 2, 2] Neck:
name: SequenceEncoder
encoder_type: rnn
hidden_size: 48
Head:
name: CTCHead
fc_decay: 0.00001Loss:
name: CTCLossPostProcess:
name: CTCLabelDecodeMetric:
name: RecMetric
main_indicator: accTrain:
dataset:
name: SimpleDataSet
data_dir: /home/aistudio/data/训练数据集/TrainImages
label_file_list: ["/home/aistudio/data/训练数据集/train.txt"] transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- RecAug:
- CTCLabelEncode: # Class handling label
- RecResizeImg:
image_shape: [3, 32, 320] - KeepKeys:
keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
loader:
shuffle: True
batch_size_per_card: 800
drop_last: True
num_workers: 4Eval:
dataset:
name: SimpleDataSet
data_dir: /home/aistudio/data/训练数据集/TrainImages
label_file_list: ["/home/aistudio/data/训练数据集/val.txt"] transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- CTCLabelEncode: # Class handling label
- RecResizeImg:
image_shape: [3, 32, 320] - KeepKeys:
keep_keys: ['image', 'label', 'length'] # dataloader will return list in this order
loader:
shuffle: False
drop_last: False
batch_size_per_card: 512
num_workers: 4
%cd ~/PaddleOCR/ !python tools/train.py -c ./configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml
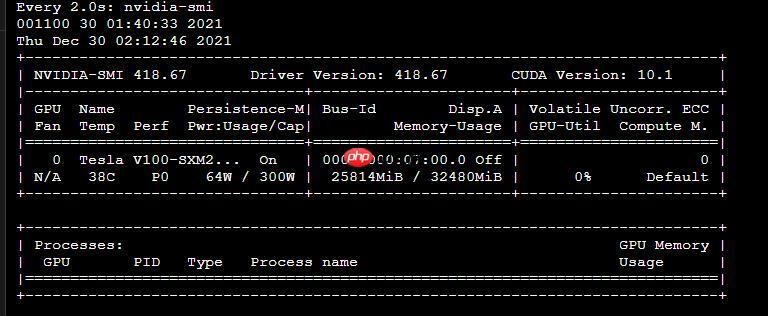
[2025/12/30 08:35:35] root INFO: Initialize indexs of datasets:['/home/aistudio/data/训练数据集/train.txt'][2025/12/30 08:36:09] root INFO: epoch: [72/500], iter: 7960, lr: 0.000958, loss: 8.251744, acc: 0.413749, norm_edit_dis: 0.679774, reader_cost: 0.71643 s, batch_cost: 1.08854 s, samples: 7200, ips: 661.43391[2025/12/30 08:36:35] root INFO: epoch: [72/500], iter: 7970, lr: 0.000958, loss: 8.213228, acc: 0.414374, norm_edit_dis: 0.681107, reader_cost: 0.01124 s, batch_cost: 0.41975 s, samples: 8000, ips: 1905.90655[2025/12/30 08:37:02] root INFO: epoch: [72/500], iter: 7980, lr: 0.000957, loss: 8.017796, acc: 0.415624, norm_edit_dis: 0.680611, reader_cost: 0.01079 s, batch_cost: 0.41746 s, samples: 8000, ips: 1916.34344[2025/12/30 08:37:28] root INFO: epoch: [72/500], iter: 7990, lr: 0.000957, loss: 8.049696, acc: 0.421249, norm_edit_dis: 0.688969, reader_cost: 0.01128 s, batch_cost: 0.41961 s, samples: 8000, ips: 1906.51883[2025/12/30 08:37:55] root INFO: epoch: [72/500], iter: 8000, lr: 0.000957, loss: 7.952358, acc: 0.421249, norm_edit_dis: 0.688969, reader_cost: 0.01156 s, batch_cost: 0.41822 s, samples: 8000, ips: 1912.88346eval model:: 100%|██████████████████████████████| 20/20 [00:28<00:00, 1.17s/it] [2025/12/30 08:38:23] root INFO: cur metric, acc: 0.6908999309100069, norm_edit_dis: 0.8983265023824453, fps: 4436.456909249088[2025/12/30 08:38:23] root INFO: s*e best model is to ./output/rec_chinese_lite_v2.0/best_accuracy
# GPU 评估, Global.checkpoints 为待测权重%cd ~/PaddleOCR/
!python -m paddle.distributed.launch tools/eval.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml \
-o Global.checkpoints=./output/rec_chinese_lite_v2.0/best_accuracy/home/aistudio/PaddleOCR
----------- Configuration Arguments -----------
backend: auto
elastic_server: None
force: False
gpus: None
heter_devices:
heter_worker_num: None
heter_workers:
host: None
http_port: None
ips: 127.0.0.1
job_id: None
log_dir: log
np: None
nproc_per_node: None
run_mode: None
scale: 0
server_num: None
servers:
training_script: tools/eval.py
training_script_args: ['-c', 'configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml', '-o', 'Global.checkpoints=./output/rec_chinese_lite_v2.0/best_accuracy']
worker_num: None
workers:
------------------------------------------------
WARNING 2025-12-30 08:49:47,054 launch.py:423] Not found distinct arguments and compiled with cuda or xpu. Default use collective mode
launch train in GPU mode!
INFO 2025-12-30 08:49:47,057 launch_utils.py:528] Local start 1 processes. First process distributed environment info (Only For Debug):
+=======================================================================================+
| Distributed Envs Value |
+---------------------------------------------------------------------------------------+
| PADDLE_TRAINER_ID 0 |
| PADDLE_CURRENT_ENDPOINT 127.0.0.1:44352 |
| PADDLE_TRAINERS_NUM 1 |
| PADDLE_TRAINER_ENDPOINTS 127.0.0.1:44352 |
| PADDLE_RANK_IN_NODE 0 |
| PADDLE_LOCAL_DEVICE_IDS 0 |
| PADDLE_WORLD_DEVICE_IDS 0 |
| FLAGS_selected_gpus 0 |
| FLAGS_selected_accelerators 0 |
+=======================================================================================+
INFO 2025-12-30 08:49:47,057 launch_utils.py:532] details abouts PADDLE_TRAINER_ENDPOINTS can be found in log/endpoints.log, and detail running logs maybe found in log/workerlog.0
launch proc_id:57223 idx:0
[2025/12/30 08:49:48] root INFO: Architecture :
[2025/12/30 08:49:48] root INFO: Backbone :
[2025/12/30 08:49:48] root INFO: model_name : small
[2025/12/30 08:49:48] root INFO: name : MobileNetV3
[2025/12/30 08:49:48] root INFO: scale : 0.5
[2025/12/30 08:49:48] root INFO: small_stride : [1, 2, 2, 2]
[2025/12/30 08:49:48] root INFO: Head :
[2025/12/30 08:49:48] root INFO: fc_decay : 1e-05
[2025/12/30 08:49:48] root INFO: name : CTCHead
[2025/12/30 08:49:48] root INFO: Neck :
[2025/12/30 08:49:48] root INFO: encoder_type : rnn
[2025/12/30 08:49:48] root INFO: hidden_size : 48
[2025/12/30 08:49:48] root INFO: name : SequenceEncoder
[2025/12/30 08:49:48] root INFO: Transform : None
[2025/12/30 08:49:48] root INFO: algorithm : CRNN
[2025/12/30 08:49:48] root INFO: model_type : rec
[2025/12/30 08:49:48] root INFO: Eval :
[2025/12/30 08:49:48] root INFO: dataset :
[2025/12/30 08:49:48] root INFO: data_dir : /home/aistudio/data/训练数据集/TrainImages
[2025/12/30 08:49:48] root INFO: label_file_list : ['/home/aistudio/data/训练数据集/val.txt']
[2025/12/30 08:49:48] root INFO: name : SimpleDataSet
[2025/12/30 08:49:48] root INFO: transforms :
[2025/12/30 08:49:48] root INFO: DecodeImage :
[2025/12/30 08:49:48] root INFO: channel_first : False
[2025/12/30 08:49:48] root INFO: img_mode : BGR
[2025/12/30 08:49:48] root INFO: CTCLabelEncode : None
[2025/12/30 08:49:48] root INFO: RecResizeImg :
[2025/12/30 08:49:48] root INFO: image_shape : [3, 32, 320]
[2025/12/30 08:49:48] root INFO: KeepKeys :
[2025/12/30 08:49:48] root INFO: keep_keys : ['image', 'label', 'length']
[2025/12/30 08:49:48] root INFO: loader :
[2025/12/30 08:49:48] root INFO: batch_size_per_card : 512
[2025/12/30 08:49:48] root INFO: drop_last : False
[2025/12/30 08:49:48] root INFO: num_workers : 4
[2025/12/30 08:49:48] root INFO: shuffle : False
[2025/12/30 08:49:48] root INFO: Global :
[2025/12/30 08:49:48] root INFO: cal_metric_during_train : True
[2025/12/30 08:49:48] root INFO: character_dict_path : ppocr/utils/ppocr_keys_v1.txt
[2025/12/30 08:49:48] root INFO: checkpoints : ./output/rec_chinese_lite_v2.0/best_accuracy
[2025/12/30 08:49:48] root INFO: debug : False
[2025/12/30 08:49:48] root INFO: distributed : False
[2025/12/30 08:49:48] root INFO: epoch_num : 500
[2025/12/30 08:49:48] root INFO: eval_batch_step : [0, 200]
[2025/12/30 08:49:48] root INFO: infer_img : doc/imgs_words/ch/word_1.jpg
[2025/12/30 08:49:48] root INFO: infer_mode : False
[2025/12/30 08:49:48] root INFO: log_smooth_window : 20
[2025/12/30 08:49:48] root INFO: max_text_length : 25
[2025/12/30 08:49:48] root INFO: pretrained_model : None
[2025/12/30 08:49:48] root INFO: print_batch_step : 10
[2025/12/30 08:49:48] root INFO: s*e_epoch_step : 3
[2025/12/30 08:49:48] root INFO: s*e_inference_dir : None
[2025/12/30 08:49:48] root INFO: s*e_model_dir : ./output/rec_chinese_lite_v2.0
[2025/12/30 08:49:48] root INFO: s*e_res_path : ./output/rec/predicts_chinese_lite_v2.0.txt
[2025/12/30 08:49:48] root INFO: use_gpu : True
[2025/12/30 08:49:48] root INFO: use_space_char : True
[2025/12/30 08:49:48] root INFO: use_visualdl : True
[2025/12/30 08:49:48] root INFO: Loss :
[2025/12/30 08:49:48] root INFO: name : CTCLoss
[2025/12/30 08:49:48] root INFO: Metric :
[2025/12/30 08:49:48] root INFO: main_indicator : acc
[2025/12/30 08:49:48] root INFO: name : RecMetric
[2025/12/30 08:49:48] root INFO: Optimizer :
[2025/12/30 08:49:48] root INFO: beta1 : 0.9
[2025/12/30 08:49:48] root INFO: beta2 : 0.999
[2025/12/30 08:49:48] root INFO: lr :
[2025/12/30 08:49:48] root INFO: learning_rate : 0.001
[2025/12/30 08:49:48] root INFO: name : Cosine
[2025/12/30 08:49:48] root INFO: warmup_epoch : 5
[2025/12/30 08:49:48] root INFO: name : Adam
[2025/12/30 08:49:48] root INFO: regularizer :
[2025/12/30 08:49:48] root INFO: factor : 1e-05
[2025/12/30 08:49:48] root INFO: name : L2
[2025/12/30 08:49:48] root INFO: PostProcess :
[2025/12/30 08:49:48] root INFO: name : CTCLabelDecode
[2025/12/30 08:49:48] root INFO: Train :
[2025/12/30 08:49:48] root INFO: dataset :
[2025/12/30 08:49:48] root INFO: data_dir : /home/aistudio/data/训练数据集/TrainImages
[2025/12/30 08:49:48] root INFO: label_file_list : ['/home/aistudio/data/训练数据集/train.txt']
[2025/12/30 08:49:48] root INFO: name : SimpleDataSet
[2025/12/30 08:49:48] root INFO: transforms :
[2025/12/30 08:49:48] root INFO: DecodeImage :
[2025/12/30 08:49:48] root INFO: channel_first : False
[2025/12/30 08:49:48] root INFO: img_mode : BGR
[2025/12/30 08:49:48] root INFO: RecAug : None
[2025/12/30 08:49:48] root INFO: CTCLabelEncode : None
[2025/12/30 08:49:48] root INFO: RecResizeImg :
[2025/12/30 08:49:48] root INFO: image_shape : [3, 32, 320]
[2025/12/30 08:49:48] root INFO: KeepKeys :
[2025/12/30 08:49:48] root INFO: keep_keys : ['image', 'label', 'length']
[2025/12/30 08:49:48] root INFO: loader :
[2025/12/30 08:49:48] root INFO: batch_size_per_card : 800
[2025/12/30 08:49:48] root INFO: drop_last : True
[2025/12/30 08:49:48] root INFO: num_workers : 4
[2025/12/30 08:49:48] root INFO: shuffle : True
[2025/12/30 08:49:48] root INFO: profiler_options : None
[2025/12/30 08:49:48] root INFO: train with paddle 2.2.1 and device CUDAPlace(0)
[2025/12/30 08:49:48] root INFO: Initialize indexs of datasets:['/home/aistudio/data/训练数据集/val.txt']
W1230 08:49:48.777415 57223 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 10.1, Runtime API Version: 10.1
W1230 08:49:48.781112 57223 device_context.cc:465] device: 0, cuDNN Version: 7.6.
[2025/12/30 08:49:52] root INFO: resume from ./output/rec_chinese_lite_v2.0/best_accuracy
[2025/12/30 08:49:52] root INFO: metric in ckpt ***************
[2025/12/30 08:49:52] root INFO: acc:0.7108999289100071
[2025/12/30 08:49:52] root INFO: norm_edit_dis:0.9080091791996405
[2025/12/30 08:49:52] root INFO: fps:4172.613918329738
[2025/12/30 08:49:52] root INFO: best_epoch:74
[2025/12/30 08:49:52] root INFO: start_epoch:75
eval model:: 0%| | 0/20 [00:00<?, ?it/s]
eval model:: 5%|▌ | 1/20 [00:02<00:48, 2.56s/it]
eval model:: 10%|█ | 2/20 [00:03<00:39, 2.19s/it]
eval model:: 15%|█▌ | 3/20 [00:05<00:32, 1.94s/it]
eval model:: 20%|██ | 4/20 [00:06<00:28, 1.76s/it]
eval model:: 25%|██▌ | 5/20 [00:07<00:24, 1.65s/it]
eval model:: 30%|███ | 6/20 [00:09<00:21, 1.57s/it]
eval model:: 35%|███▌ | 7/20 [00:10<00:19, 1.51s/it]
eval model:: 40%|████ | 8/20 [00:12<00:17, 1.47s/it]
eval model:: 45%|████▌ | 9/20 [00:13<00:15, 1.43s/it]
eval model:: 50%|█████ | 10/20 [00:14<00:14, 1.40s/it]
eval model:: 55%|█████▌ | 11/20 [00:16<00:12, 1.39s/it]
eval model:: 60%|██████ | 12/20 [00:17<00:10, 1.37s/it]
eval model:: 65%|██████▌ | 13/20 [00:18<00:09, 1.36s/it]
eval model:: 70%|███████ | 14/20 [00:20<00:08, 1.36s/it]
eval model:: 75%|███████▌ | 15/20 [00:21<00:06, 1.36s/it]
eval model:: 80%|████████ | 16/20 [00:22<00:05, 1.35s/it]
eval model:: 85%|████████▌ | 17/20 [00:24<00:04, 1.35s/it]
eval model:: 90%|█████████ | 18/20 [00:25<00:02, 1.35s/it]
eval model:: 95%|█████████▌| 19/20 [00:26<00:01, 1.35s/it]
eval model:: 100%|██████████| 20/20 [00:27<00:00, 1.16s/it]
[2025/12/30 08:50:20] root INFO: metric eval ***************
[2025/12/30 08:50:20] root INFO: acc:0.7108999289100071
[2025/12/30 08:50:20] root INFO: norm_edit_dis:0.9080091791996405
[2025/12/30 08:50:20] root INFO: fps:4556.466541403698
INFO 2025-12-30 08:50:23,113 launch.py:311] Local processes completed.
预测脚本使用预测训练好的模型,并将结果保存成txt格式,可以直接送到比赛提交入口测评,文件默认保存在output/rec/predicts_chinese_lite_v2.0.txt
In [ ]!python tools/infer_rec.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml \
-o Global.infer_img="/home/aistudio/data/A榜测试数据集/TestAImages" \
Global.pretrained_model="./outpu t/rec_chinese_lite_v2.0/latest.pdparams"
t/rec_chinese_lite_v2.0/latest.pdparams"
预测日志
[2025/12/30 08:52:55] root INFO: result: 门 0.5737782[2025/12/30 08:52:55] root INFO: infer_img: /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000704.jpg [2025/12/30 08:52:55] root INFO: result: 红豆米营美码 0.5796438[2025/12/30 08:52:55] root INFO: infer_img: /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000705.jpg [2025/12/30 08:52:55] root INFO: result: 少年成长加油站 0.95518243[2025/12/30 08:52:55] root INFO: infer_img: /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000706.jpg [2025/12/30 08:52:55] root INFO: result: 展板奖牌铜牌活动策划 0.6614779[2025/12/30 08:52:55] root INFO: infer_img: /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000707.jpg [2025/12/30 08:52:55] root INFO: result: USG铁工代室 0.61983764[2025/12/30 08:52:55] root INFO: infer_img: /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000708.jpg [2025/12/30 08:52:55] root INFO: result: 家部 0.10427441[2025/12/30 08:52:55] root INFO: infer_img: /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000709.jpg ... ...
约束性条件1:模型总大小不超过10MB(以.pdmodel和.pdiparams文件非压缩状态磁盘占用空间之和为准);
训练过程中保存的模型是checkpoints模型,保存的只有模型的参数,多用于恢复训练等。实际上,此处的约束条件限制的是inference 模型的大小。inference 模型一般是模型训练,把模型结构和模型参数保存在文件中的固化模型,多用于预测部署场景。与checkpoints模型相比,inference 模型会额外保存模型的结构信息,在预测部署、加速推理上性能优越,灵活方便,适合于实际系统集成,模型大小也会小一些。
In [ ]# 静态模型导出%cd ~/PaddleOCR/ !python tools/export_model.py -c configs/rec/ch_ppocr_v2.0/rec_chinese_lite_train_v2.0.yml -o Global.pretrained_model=./output/rec_chinese_lite_v2.0/latest.pdparams Global.s*e_inference_dir=./inference/rec_inference/
/home/aistudio/PaddleOCR W1230 13:19:16.513371 531 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.0, Runtime API Version: 10.1 W1230 13:19:16.517957 531 device_context.cc:465] device: 0, cuDNN Version: 7.6. [2025/12/30 13:19:19] root INFO: load pretrain successful from ./output/rec_chinese_lite_v2.0/latest [2025/12/30 13:19:21] root INFO: inference model is s*ed to ./inference/rec_inference/inferenceIn [13]
%cd ~/PaddleOCR/ !du -sh ./inference/rec_inference/
/home/aistudio/PaddleOCR 5.2M ./inference/rec_inference/
# 使用导出静态模型预测%cd ~/PaddleOCR/ !python3.7 tools/infer/predict_rec.py --rec_model_dir=./inference/rec_inference/ --image_dir="/home/aistudio/data/A榜测试数据集/TestAImages"
预测日志
[2025/12/30 13:20:08] root INFO: Predicts of /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000001.jpg:('MJ', 0.2357887)
[2025/12/30 13:20:08] root INFO: Predicts of /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000002.jpg:('中门', 0.7167614)
[2025/12/30 13:20:08] root INFO: Predicts of /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000003.jpg:('黄焖鸡米饭', 0.7325407)
[2025/12/30 13:20:08] root INFO: Predicts of /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000004.jpg:('加行', 0.06699998)
[2025/12/30 13:20:08] root INFO: Predicts of /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000005.jpg:('学商烤面航', 0.40579563)
[2025/12/30 13:20:08] root INFO: Predicts of /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000006.jpg:('绿村装机 滋光彩机 CP口出国', 0.38243735)
[2025/12/30 13:20:08] root INFO: Predicts of /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000007.jpg:('有酸锁 四好吃', 0.38957664)
[2025/12/30 13:20:08] root INFO: Predicts of /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000008.jpg:('婚汽中海', 0.36037388)
[2025/12/30 13:20:08] root INFO: Predicts of /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000009.jpg:('L', 0.25453746)
[2025/12/30 13:20:08] root INFO: Predicts of /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000010.jpg:('清女装', 0.79736567)
[2025/12/30 13:20:08] root INFO: Predicts of /home/aistudio/data/A榜测试数据集/TestAImages/TestA_000011.jpg:('幼小数学视食', 0.50577885)
...
...以上就是基于PaddleOCR2.4的轻量级文字识别技术创新大赛Baseline的详细内容,更多请关注其它相关文章!
# git
# 是在
# 的是
# 官网
# 解决办法
# 多线程
# 一言
# 万张
# 测试数据
# 中文网
# fig
# udio
# igs
# red
# cos
# ai
# 工具
# 浏览器
# python
# type
# 站长工具seo在线
# 巴中网站建设运营方案
# 崇明区市场营销策划推广
# 如何做订阅网站推广
# 简述seo与sem
# net cn seo
# 索罗斯科技seo
# 软件推广营销视频
# 学习seo知识不能盲目
# 如何优化推广网站排名
# 也有
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
苹果机器学习关键人物 Ali Farhadi 离职,回归 AI2 担任 CEO
当孔子遇见AI|尼山的“数字”
“一般智力”与工艺学批判是认识AI的重要入口 | 社会科学报
以分布式网络串联闲置GPU,这家创企称可将AI模型训练成本降低90%
意大利警察拟用AI预测犯罪 该算法被指种族歧视严重
AYANEO AIR 1S 掌机发布:R7 7840U,预订价 4699 元起
微软和谷歌面临的人工智能困境:需要投入大量资金才能获得盈利
AI创作广告文案等同2.47年工作经验,且消费者无法区分|AI营销前沿
创新全场景清洁方案!海尔商用机器人首发上市
中国AI公有云市场2025年逆势蓬勃增长,增速高达80.6%
马斯克称未来机器人数量将多于人类,特斯拉愿共享自动驾驶技术
AI生成新闻网站数量激增,正在疯狂赚取广告收入
小米创始人雷军将揭示小米AI在年度演讲中的最新进展
精准度可提高 20%:英国九家银行签约使用基于 AI 的“消费者欺诈风险系统”应对*
在心理治疗中用VR技术,治疗成效显著提高
东软成立魔形科技研究院,积极布局大语言模型系统工程战略,迎接AI时代
酒店业将如何受益于人工智能的改变?
上海发布“元宇宙关键技术攻关行动方案”,加快 AIGC 等突破
当一切设备都受到人工智能的控制
微软在 Bing 和 Edge 浏览器中拓展网购服务,帮用户选购心仪产品
CharacterAI - 也许会成为会话人工智能的未来
标小智LOGO推出AI公司起名生成器“Name.GPT”
人工智能驱动艺术,打开达利的超现实想象
基于信息论的校准技术,CML让多模态机器学习更可靠
WPS AI 官网上线:可申请体验官资格,支持 Windows、安卓端下载
DeepMind推惊世排序算法,C++库忙更新!
无人机协助盐城交通执法的协同训练
人工智能即将进入Windows:企业准备好安全策略设置了吗?
实践J*a开发,构建高性能的MongoDB数据迁移工具
如何获得元宇宙的第一个属于自己的空间
百亿量化私募:量化投资进入“精耕细作”时代 AI带来行业新变革
全国体育人工智能大会举办,专家聚焦体育人工智能领域人才培养
美图设计室2.0什么时候上线
天翼云在国际AI顶会大模型挑战赛中获得冠军
郭帆:AI发展日新月异,或是弯道超车好莱坞的最好机会
Prompt解锁语音语言模型生成能力,SpeechGen实现语音翻译、修补多项任务
美图秀秀发布7款AI产品:支持用户创作、商业创作
国内首家,360智脑通过中国信通院可信AIGC大语言模型功能评估
应对算力挑战,亚马逊云科技发力AI基础设施建设
Xbox游戏工作室负责人:VR/AR领域的用户规模还不足够
食品分销跨国企业Sysco CIDO:我们的增长秘诀是以IT为中心
全面拥抱大模型浪潮,ISC 2025打造全球首场AI数字安全峰会
字节团队提出猞猁Lynx模型:多模态LLMs理解认知生成类榜单SoTA
新华全媒+|AI:当心,我可能欺骗了你!
华为云天筹AI求解器荣获世界人工智能大会最高奖
探索AI前沿理念 2025全球人工智能技术大会在杭州开幕
热点 | 人工智能黄金时代开启
拓普龙7188ML:轻便壁挂式工控机箱,为人工智能应用场景提供有力保障
为了避免人工智能可能带来的灾难,我们要向核安全学习
鹅厂机器狗抢起真狗「饭碗」!会撒欢儿做游戏,遛人也贼6
 当前位置:
当前位置:  t/rec_chinese_lite_v2.0/latest.pdparams"
t/rec_chinese_lite_v2.0/latest.pdparams" 上一篇:
上一篇: 返回列表
返回列表