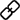400 128 6709

行业新闻
 发布时间:2025-07-29
发布时间:2025-07-29 点击次数:
点击次数: 本文复现了ResNet50-NAM模型,其引入基于归一化的注意力机制(NAM),利用Batch Normalization的缩放因子计算通道注意力,避免额外全连接层和卷积层。在CIFAR100数据集上,将ResNet第一层卷积调整为3×3小核,去掉maxpooling层,经训练,该模型相比原始ResNet50效果提升,且缓解过拟合。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文地址:https://arxiv.org/abs/2111.12419
注意力机制在近年来大热,注意力机制可以帮助神经网络抑制通道中或者是空间中不太显著的特征。之前的很多的研究聚焦于如何通过注意力算子来获取显著性的特征。这些方法成功的发现了特征的不同维度之间的互信息量。但是,缺乏对权值的贡献因子的考虑,而这个贡献因子可以进一步的抑制不显著的特征。因此,我们瞄准了利用权值的贡献因子来提升注意力的效果。我们使用了Batch Normalization的缩放因子来表示权值的重要程度。这样可以避免如SE,BAM和CBAM一样增加全连接层和卷积层。这样,我们提出了一个新的注意力方式:基于归一化的注意力(NAM)。
我们提出的NAM是一种轻量级的高效的注意力机制,我们采用了CBAM的模块集成方式,重新设计了通道注意力和空间注意力子模块,这样,NAM可以嵌入到每个网络block的最后。对于残差网络,可以嵌入到残差结构的最后。对于通道注意力子模块,我们使用了Batch Normalization中的缩放因子,如式子(1),缩放因子反映出各个通道的变化的大小,也表示了该通道的重要性。为什么这么说呢,可以这样理解,缩放因子即BN中的方差,方差越大表示该通道变化的越厉害,那么该通道中包含的信息会越丰富,重要性也越大,而那些变化不大的通道,信息单一,重要性小。
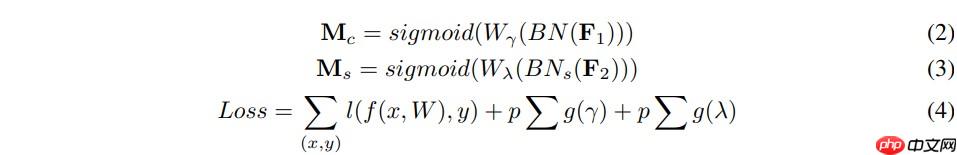
其中μB和σB为均值,B为标准差,γ和β是可训练的仿射变换参数(尺度和位移)参考Batch Normalization.通道注意力子模块如图(1)和式(2)所示: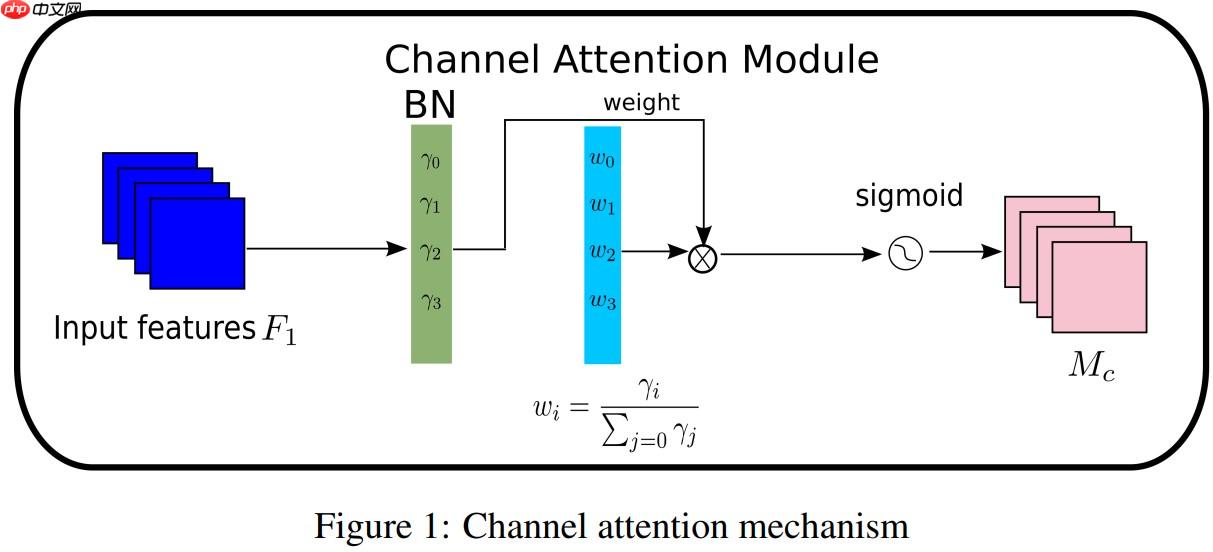 其中Mc表示最后得到的输出特征,γ是每个通道的缩放因子,因此,每个通道的权值可以通过 Wγ=γi/∑j=0γj 得到。我们也使用一个缩放因子 BN 来计算注意力权重,称为像素归一化。像素注意力如图(2)和式(3)所示:
其中Mc表示最后得到的输出特征,γ是每个通道的缩放因子,因此,每个通道的权值可以通过 Wγ=γi/∑j=0γj 得到。我们也使用一个缩放因子 BN 来计算注意力权重,称为像素归一化。像素注意力如图(2)和式(3)所示: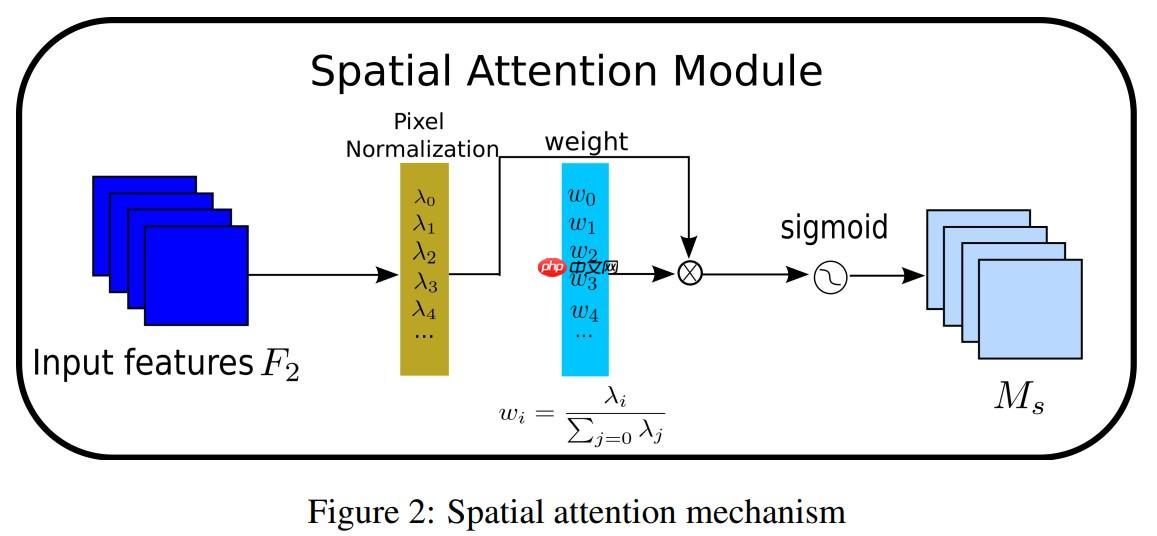
为了抑制不重要的特征,作者在损失函数中加入了一个正则化项,如式(4)所示。
链接:http://www.cs.toronto.edu/~kriz/cifar.html

CIFAR100数据集有100个类。每个类有600张大小为32 × 32 32\times 3232×32的彩色图像,其中500张作为训练集,100张作为测试集。
from __future__ import divisionfrom __future__ import print_functionimport paddleimport paddle.nn as nnfrom paddle.nn import functional as Ffrom paddle.utils.download import get_weights_path_from_urlimport pickleimport numpy as npfrom paddle import callbacksfrom paddle.vision.transforms import (
ToTensor, RandomHorizontalFlip, RandomResizedCrop, SaturationTransform, Compose,
HueTransform, BrightnessTransform, ContrastTransform, RandomCrop, Normalize, RandomRotation
)from paddle.vision.datasets import Cifar100from paddle.io import DataLoaderfrom paddle.optimizer.lr import CosineAnnealingDecay, MultiStepDecay, LinearWarmupimport random
它抑制了较少显著性的权值,对注意力模块应用一个权重稀疏惩罚
In [2]class Channel_Att(nn.Layer):
def __init__(self, channels=3, t=16):
super(Channel_Att, self).__init__()
self.channels = channels
self.bn2 = nn.BatchNorm2D(self.channels) def forward(self, x):
residual = x
x = self.bn2(x)
weight_bn = self.bn2.weight.abs() / paddle.sum(self.bn2.weight.abs())
x = x.transpose([0, 2, 3, 1])
x = paddle.multiply(weight_bn, x)
x = x.transpose([0, 3, 1, 2])
x = F.sigmoid(x) * residual #
return xclass Att(nn.Layer):
def __init__(self, channels=3, out_channels=None, no_spatial=True):
super(Att, self).__init__()
self.Channel_Att = Channel_Att(channels)
def forward(self, x):
x_out1=self.Channel_Att(x) return x_out1
本代码参考Paddleclas实现,代码中将分类类别设定为100类
 简小派
简小派
简小派是一款AI原生求职工具,通过简历优化、岗位匹配、项目生成、模拟面试与智能投递,全链路提升求职成功率,帮助普通人更快拿到更好的 offer。
 123
查看详情
123
查看详情

由于CIFAR100输入均为32x32的图像,而原始的ResNet第一层卷积是7X7的大核卷积,这样的卷积结构对于CIFAR100数据集性能表现较差。因此,我们参照:https://github.com/weiaicunzai/pytorch-cifar100 中的做法,将ResNet第一层卷积改为kernel_size=3,stride=1,padding=1的卷积,并去掉之后的maxpooling层
In [3]__all__ = []
model_urls = { 'resnet18': ('https://paddle-hapi.bj.bcebos.com/models/resnet18.pdparams', 'cf548f46534aa3560945be4b95cd11c4'), 'resnet34': ('https://paddle-hapi.bj.bcebos.com/models/resnet34.pdparams', '8d2275cf8706028345f78ac0e1d31969'), 'resnet50': ('https://paddle-hapi.bj.bcebos.com/models/resnet50.pdparams', 'ca6f485ee1ab0492d38f323885b0ad80'), 'resnet101': ('https://paddle-hapi.bj.bcebos.com/models/resnet101.pdparams', '02f35f034ca3858e1e54d4036443c92d'), 'resnet152': ('https://paddle-hapi.bj.bcebos.com/models/resnet152.pdparams', '7ad16a2f1e7333859ff986138630fd7a'),
}class BasicBlock(nn.Layer):
expansion = 1
def __init__(self,
inplanes,
planes,
stride=1,
downsample=None,
groups=1,
base_width=64,
dilation=1,
norm_layer=None):
super(BasicBlock, self).__init__() if norm_layer is None:
norm_layer = nn.BatchNorm2D if dilation > 1: raise NotImplementedError( "Dilation > 1 not supported in BasicBlock")
self.conv1 = nn.Conv2D(
inplanes, planes, 3, padding=1, stride=stride, bias_attr=False)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU()
self.conv2 = nn.Conv2D(planes, planes, 3, padding=1, bias_attr=False)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
self.nam = Att(planes) def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out) if self.downsample is not None:
identity = self.downsample(x)
out = self.nam(out)
out += identity
out = self.relu(out) return outclass BottleneckBlock(nn.Layer):
expansion = 4
def __init__(self,
inplanes,
planes,
stride=1,
downsample=None,
groups=1,
base_width=64,
dilation=1,
norm_layer=None):
super(BottleneckBlock, self).__init__() if norm_layer is None:
norm_layer = nn.BatchNorm2D
width = int(planes * (base_width / 64.)) * groups
self.conv1 = nn.Conv2D(inplanes, width, 1, bias_attr=False)
self.bn1 = norm_layer(width)
self.conv2 = nn.Conv2D(
width,
width, 3,
padding=dilation,
stride=stride,
groups=groups,
dilation=dilation,
bias_attr=False)
self.bn2 = norm_layer(width)
self.conv3 = nn.Conv2D(
width, planes * self.expansion, 1, bias_attr=False)
self.bn3 = norm_layer(planes * self.expansion)
self.relu = nn.ReLU()
self.downsample = downsample
self.stride = stride
self.nam = Att(planes*4) def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out) if self.downsample is not None:
identity = self.downsample(x)
out = self.nam(out)
out += identity
out = self.relu(out) return outclass ResNet(nn.Layer):
"""ResNet model from
`"Deep Residual Learning for Image Recognition" <https://arxiv.org/pdf/1512.03385.pdf>`_
Args:
Block (BasicBlock|BottleneckBlock): block module of model.
depth (int): layers of resnet, default: 50.
num_classes (int): output dim of last fc layer. If num_classes <=0, last fc layer
will not be defined. Default: 1000.
with_pool (bool): use pool before the last fc layer or not. Default: True.
Examples:
.. code-block:: python
from paddle.vision.models import ResNet
from paddle.vision.models.resnet import BottleneckBlock, BasicBlock
resnet50 = ResNet(BottleneckBlock, 50)
resnet18 = ResNet(BasicBlock, 18)
"""
def __init__(self, block, depth, num_classes=100, with_pool=True):
super(ResNet, self).__init__()
layer_cfg = { 18: [2, 2, 2, 2], 34: [3, 4, 6, 3], 50: [3, 4, 6, 3], 101: [3, 4, 23, 3], 152: [3, 8, 36, 3]
}
layers = layer_cfg[depth]
self.num_classes = num_classes
self.with_pool = with_pool
self._norm_layer = nn.BatchNorm2D
self.inplanes = 64
self.dilation = 1
###
# 将大核卷积改为小核卷积
###
self.conv1 = nn.Conv2D( 3,
self.inplanes,
kernel_size=3,
stride=1,
padding=1,
bias_attr=False)
self.bn1 = self._norm_layer(self.inplanes)
self.relu = nn.ReLU() ###
# 去掉第一层池化
###
# self.maxpool = nn.MaxPool2D(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2) if with_pool:
self.*gpool = nn.AdaptiveAvgPool2D((1, 1)) if num_classes > 0:
self.fc = nn.Linear(512 * block.expansion, num_classes) def _make_layer(self, block, planes, blocks, stride=1, dilate=False):
norm_layer = self._norm_layer
downsample = None
previous_dilation = self.dilation if dilate:
self.dilation *= stride
stride = 1
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2D(
self.inplanes,
planes * block.expansion, 1,
stride=stride,
bias_attr=False),
norm_layer(planes * block.expansion), )
layers = []
layers.append(
block(self.inplanes, planes, stride, downsample, 1, 64,
previous_dilation, norm_layer))
self.inplanes = planes * block.expansion for _ in range(1, blocks):
layers.append(block(self.inplanes, planes, norm_layer=norm_layer)) return nn.Sequential(*layers) def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x) ###
# 去掉池化
###
# x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x) if self.with_pool:
x = self.*gpool(x) if self.num_classes > 0:
x = paddle.flatten(x, 1)
x = self.fc(x) return xdef _resnet(arch, Block, depth, pretrained, **kwargs):
model = ResNet(Block, depth, **kwargs) if pretrained: assert arch in model_urls, "{} model do not h*e a pretrained model now, you should set pretrained=False".format(
arch)
weight_path = get_weights_path_from_url(model_urls[arch][0],
model_urls[arch][1])
param = paddle.load(weight_path)
model.set_dict(param) return modeldef resnet50(pretrained=False, **kwargs):
"""ResNet 50-layer model
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
Examples:
.. code-block:: python
from paddle.vision.models import resnet50
# build model
model = resnet50()
# build model and load imagenet pretrained weight
# model = resnet50(pretrained=True)
"""
return _resnet('resnet50', BottleneckBlock, 50, pretrained, **kwargs)def resnet18(pretrained=False, **kwargs):
"""ResNet 18-layer model
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
Examples:
.. code-block:: python
from paddle.vision.models import resnet18
# build model
model = resnet18()
# build model and load imagenet pretrained weight
# model = resnet18(pretrained=True)
"""
return _resnet('resnet18', BasicBlock, 18, pretrained, **kwargs)
In [4]
net = resnet50() paddle.summary(net, (1,3,32,32))
W0616 11:51:50.953474 25258 gpu_context.cc:278] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1 W0616 11:51:50.958021 25258 gpu_context.cc:306] device: 0, cuDNN Version: 7.6.
-------------------------------------------------------------------------------
Layer (type) Input Shape Output Shape Param #
===============================================================================
Conv2D-1 [[1, 3, 32, 32]] [1, 64, 32, 32] 1,728
BatchNorm2D-1 [[1, 64, 32, 32]] [1, 64, 32, 32] 256
ReLU-1 [[1, 64, 32, 32]] [1, 64, 32, 32] 0
Conv2D-3 [[1, 64, 32, 32]] [1, 64, 32, 32] 4,096
BatchNorm2D-3 [[1, 64, 32, 32]] [1, 64, 32, 32] 256
ReLU-2 [[1, 256, 32, 32]] [1, 256, 32, 32] 0
Conv2D-4 [[1, 64, 32, 32]] [1, 64, 32, 32] 36,864
BatchNorm2D-4 [[1, 64, 32, 32]] [1, 64, 32, 32] 256
Conv2D-5 [[1, 64, 32, 32]] [1, 256, 32, 32] 16,384
BatchNorm2D-5 [[1, 256, 32, 32]] [1, 256, 32, 32] 1,024
Conv2D-2 [[1, 64, 32, 32]] [1, 256, 32, 32] 16,384
BatchNorm2D-2 [[1, 256, 32, 32]] [1, 256, 32, 32] 1,024
BatchNorm2D-6 [[1, 256, 32, 32]] [1, 256, 32, 32] 1,024
Channel_Att-1 [[1, 256, 32, 32]] [1, 256, 32, 32] 0
Att-1 [[1, 256, 32, 32]] [1, 256, 32, 32] 0
BottleneckBlock-1 [[1, 64, 32, 32]] [1, 256, 32, 32] 0
Conv2D-6 [[1, 256, 32, 32]] [1, 64, 32, 32] 16,384
BatchNorm2D-7 [[1, 64, 32, 32]] [1, 64, 32, 32] 256
ReLU-3 [[1, 256, 32, 32]] [1, 256, 32, 32] 0
Conv2D-7 [[1, 64, 32, 32]] [1, 64, 32, 32] 36,864
BatchNorm2D-8 [[1, 64, 32, 32]] [1, 64, 32, 32] 256
Conv2D-8 [[1, 64, 32, 32]] [1, 256, 32, 32] 16,384
BatchNorm2D-9 [[1, 256, 32, 32]] [1, 256, 32, 32] 1,024
BatchNorm2D-10 [[1, 256, 32, 32]] [1, 256, 32, 32] 1,024
Channel_Att-2 [[1, 256, 32, 32]] [1, 256, 32, 32] 0
Att-2 [[1, 256, 32, 32]] [1, 256, 32, 32] 0
BottleneckBlock-2 [[1, 256, 32, 32]] [1, 256, 32, 32] 0
Conv2D-9 [[1, 256, 32, 32]] [1, 64, 32, 32] 16,384
BatchNorm2D-11 [[1, 64, 32, 32]] [1, 64, 32, 32] 256
ReLU-4 [[1, 256, 32, 32]] [1, 256, 32, 32] 0
Conv2D-10 [[1, 64, 32, 32]] [1, 64, 32, 32] 36,864
BatchNorm2D-12 [[1, 64, 32, 32]] [1, 64, 32, 32] 256
Conv2D-11 [[1, 64, 32, 32]] [1, 256, 32, 32] 16,384
BatchNorm2D-13 [[1, 256, 32, 32]] [1, 256, 32, 32] 1,024
BatchNorm2D-14 [[1, 256, 32, 32]] [1, 256, 32, 32] 1,024
Channel_Att-3 [[1, 256, 32, 32]] [1, 256, 32, 32] 0
Att-3 [[1, 256, 32, 32]] [1, 256, 32, 32] 0
BottleneckBlock-3 [[1, 256, 32, 32]] [1, 256, 32, 32] 0
Conv2D-13 [[1, 256, 32, 32]] [1, 128, 32, 32] 32,768
BatchNorm2D-16 [[1, 128, 32, 32]] [1, 128, 32, 32] 512
ReLU-5 [[1, 512, 16, 16]] [1, 512, 16, 16] 0
Conv2D-14 [[1, 128, 32, 32]] [1, 128, 16, 16] 147,456
BatchNorm2D-17 [[1, 128, 16, 16]] [1, 128, 16, 16] 512
Conv2D-15 [[1, 128, 16, 16]] [1, 512, 16, 16] 65,536
BatchNorm2D-18 [[1, 512, 16, 16]] [1, 512, 16, 16] 2,048
Conv2D-12 [[1, 256, 32, 32]] [1, 512, 16, 16] 131,072
BatchNorm2D-15 [[1, 512, 16, 16]] [1, 512, 16, 16] 2,048
BatchNorm2D-19 [[1, 512, 16, 16]] [1, 512, 16, 16] 2,048
Channel_Att-4 [[1, 512, 16, 16]] [1, 512, 16, 16] 0
Att-4 [[1, 512, 16, 16]] [1, 512, 16, 16] 0
BottleneckBlock-4 [[1, 256, 32, 32]] [1, 512, 16, 16] 0
Conv2D-16 [[1, 512, 16, 16]] [1, 128, 16, 16] 65,536
BatchNorm2D-20 [[1, 128, 16, 16]] [1, 128, 16, 16] 512
ReLU-6 [[1, 512, 16, 16]] [1, 512, 16, 16] 0
Conv2D-17 [[1, 128, 16, 16]] [1, 128, 16, 16] 147,456
BatchNorm2D-21 [[1, 128, 16, 16]] [1, 128, 16, 16] 512
Conv2D-18 [[1, 128, 16, 16]] [1, 512, 16, 16] 65,536
BatchNorm2D-22 [[1, 512, 16, 16]] [1, 512, 16, 16] 2,048
BatchNorm2D-23 [[1, 512, 16, 16]] [1, 512, 16, 16] 2,048
Channel_Att-5 [[1, 512, 16, 16]] [1, 512, 16, 16] 0
Att-5 [[1, 512, 16, 16]] [1, 512, 16, 16] 0
BottleneckBlock-5 [[1, 512, 16, 16]] [1, 512, 16, 16] 0
Conv2D-19 [[1, 512, 16, 16]] [1, 128, 16, 16] 65,536
BatchNorm2D-24 [[1, 128, 16, 16]] [1, 128, 16, 16] 512
ReLU-7 [[1, 512, 16, 16]] [1, 512, 16, 16] 0
Conv2D-20 [[1, 128, 16, 16]] [1, 128, 16, 16] 147,456
BatchNorm2D-25 [[1, 128, 16, 16]] [1, 128, 16, 16] 512
Conv2D-21 [[1, 128, 16, 16]] [1, 512, 16, 16] 65,536
BatchNorm2D-26 [[1, 512, 16, 16]] [1, 512, 16, 16] 2,048
BatchNorm2D-27 [[1, 512, 16, 16]] [1, 512, 16, 16] 2,048
Channel_Att-6 [[1, 512, 16, 16]] [1, 512, 16, 16] 0
Att-6 [[1, 512, 16, 16]] [1, 512, 16, 16] 0
BottleneckBlock-6 [[1, 512, 16, 16]] [1, 512, 16, 16] 0
Conv2D-22 [[1, 512, 16, 16]] [1, 128, 16, 16] 65,536
BatchNorm2D-28 [[1, 128, 16, 16]] [1, 128, 16, 16] 512
ReLU-8 [[1, 512, 16, 16]] [1, 512, 16, 16] 0
Conv2D-23 [[1, 128, 16, 16]] [1, 128, 16, 16] 147,456
BatchNorm2D-29 [[1, 128, 16, 16]] [1, 128, 16, 16] 512
Conv2D-24 [[1, 128, 16, 16]] [1, 512, 16, 16] 65,536
BatchNorm2D-30 [[1, 512, 16, 16]] [1, 512, 16, 16] 2,048
BatchNorm2D-31 [[1, 512, 16, 16]] [1, 512, 16, 16] 2,048
Channel_Att-7 [[1, 512, 16, 16]] [1, 512, 16, 16] 0
Att-7 [[1, 512, 16, 16]] [1, 512, 16, 16] 0
BottleneckBlock-7 [[1, 512, 16, 16]] [1, 512, 16, 16] 0
Conv2D-26 [[1, 512, 16, 16]] [1, 256, 16, 16] 131,072
BatchNorm2D-33 [[1, 256, 16, 16]] [1, 256, 16, 16] 1,024
ReLU-9 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
Conv2D-27 [[1, 256, 16, 16]] [1, 256, 8, 8] 589,824
BatchNorm2D-34 [[1, 256, 8, 8]] [1, 256, 8, 8] 1,024
Conv2D-28 [[1, 256, 8, 8]] [1, 1024, 8, 8] 262,144
BatchNorm2D-35 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 4,096
Conv2D-25 [[1, 512, 16, 16]] [1, 1024, 8, 8] 524,288
BatchNorm2D-32 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 4,096
BatchNorm2D-36 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 4,096
Channel_Att-8 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
Att-8 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
BottleneckBlock-8 [[1, 512, 16, 16]] [1, 1024, 8, 8] 0
Conv2D-29 [[1, 1024, 8, 8]] [1, 256, 8, 8] 262,144
BatchNorm2D-37 [[1, 256, 8, 8]] [1, 256, 8, 8] 1,024
ReLU-10 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
Conv2D-30 [[1, 256, 8, 8]] [1, 256, 8, 8] 589,824
BatchNorm2D-38 [[1, 256, 8, 8]] [1, 256, 8, 8] 1,024
Conv2D-31 [[1, 256, 8, 8]] [1, 1024, 8, 8] 262,144
BatchNorm2D-39 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 4,096
BatchNorm2D-40 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 4,096
Channel_Att-9 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
Att-9 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
BottleneckBlock-9 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
Conv2D-32 [[1, 1024, 8, 8]] [1, 256, 8, 8] 262,144
BatchNorm2D-41 [[1, 256, 8, 8]] [1, 256, 8, 8] 1,024
ReLU-11 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
Conv2D-33 [[1, 256, 8, 8]] [1, 256, 8, 8] 589,824
BatchNorm2D-42 [[1, 256, 8, 8]] [1, 256, 8, 8] 1,024
Conv2D-34 [[1, 256, 8, 8]] [1, 1024, 8, 8] 262,144
BatchNorm2D-43 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 4,096
BatchNorm2D-44 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 4,096
Channel_Att-10 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
Att-10 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
BottleneckBlock-10 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
Conv2D-35 [[1, 1024, 8, 8]] [1, 256, 8, 8] 262,144
BatchNorm2D-45 [[1, 256, 8, 8]] [1, 256, 8, 8] 1,024
ReLU-12 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
Conv2D-36 [[1, 256, 8, 8]] [1, 256, 8, 8] 589,824
BatchNorm2D-46 [[1, 256, 8, 8]] [1, 256, 8, 8] 1,024
Conv2D-37 [[1, 256, 8, 8]] [1, 1024, 8, 8] 262,144
BatchNorm2D-47 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 4,096
BatchNorm2D-48 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 4,096
Channel_Att-11 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
Att-11 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
BottleneckBlock-11 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
Conv2D-38 [[1, 1024, 8, 8]] [1, 256, 8, 8] 262,144
BatchNorm2D-49 [[1, 256, 8, 8]] [1, 256, 8, 8] 1,024
ReLU-13 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
Conv2D-39 [[1, 256, 8, 8]] [1, 256, 8, 8] 589,824
BatchNorm2D-50 [[1, 256, 8, 8]] [1, 256, 8, 8] 1,024
Conv2D-40 [[1, 256, 8, 8]] [1, 1024, 8, 8] 262,144
BatchNorm2D-51 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 4,096
BatchNorm2D-52 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 4,096
Channel_Att-12 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
Att-12 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
BottleneckBlock-12 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
Conv2D-41 [[1, 1024, 8, 8]] [1, 256, 8, 8] 262,144
BatchNorm2D-53 [[1, 256, 8, 8]] [1, 256, 8, 8] 1,024
ReLU-14 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
Conv2D-42 [[1, 256, 8, 8]] [1, 256, 8, 8] 589,824
BatchNorm2D-54 [[1, 256, 8, 8]] [1, 256, 8, 8] 1,024
Conv2D-43 [[1, 256, 8, 8]] [1, 1024, 8, 8] 262,144
BatchNorm2D-55 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 4,096
BatchNorm2D-56 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 4,096
Channel_Att-13 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
Att-13 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
BottleneckBlock-13 [[1, 1024, 8, 8]] [1, 1024, 8, 8] 0
Conv2D-45 [[1, 1024, 8, 8]] [1, 512, 8, 8] 524,288
BatchNorm2D-58 [[1, 512, 8, 8]] [1, 512, 8, 8] 2,048
ReLU-15 [[1, 2048, 4, 4]] [1, 2048, 4, 4] 0
Conv2D-46 [[1, 512, 8, 8]] [1, 512, 4, 4] 2,359,296
BatchNorm2D-59 [[1, 512, 4, 4]] [1, 512, 4, 4] 2,048
Conv2D-47 [[1, 512, 4, 4]] [1, 2048, 4, 4] 1,048,576
BatchNorm2D-60 [[1, 2048, 4, 4]] [1, 2048, 4, 4] 8,192
Conv2D-44 [[1, 1024, 8, 8]] [1, 2048, 4, 4] 2,097,152
BatchNorm2D-57 [[1, 2048, 4, 4]] [1, 2048, 4, 4] 8,192
BatchNorm2D-61 [[1, 2048, 4, 4]] [1, 2048, 4, 4] 8,192
Channel_Att-14 [[1, 2048, 4, 4]] [1, 2048, 4, 4] 0
Att-14 [[1, 2048, 4, 4]] [1, 2048, 4, 4] 0
BottleneckBlock-14 [[1, 1024, 8, 8]] [1, 2048, 4, 4] 0
Conv2D-48 [[1, 2048, 4, 4]] [1, 512, 4, 4] 1,048,576
BatchNorm2D-62 [[1, 512, 4, 4]] [1, 512, 4, 4] 2,048
ReLU-16 [[1, 2048, 4, 4]] [1, 2048, 4, 4] 0
Conv2D-49 [[1, 512, 4, 4]] [1, 512, 4, 4] 2,359,296
BatchNorm2D-63 [[1, 512, 4, 4]] [1, 512, 4, 4] 2,048
Conv2D-50 [[1, 512, 4, 4]] [1, 2048, 4, 4] 1,048,576
BatchNorm2D-64 [[1, 2048, 4, 4]] [1, 2048, 4, 4] 8,192
BatchNorm2D-65 [[1, 2048, 4, 4]] [1, 2048, 4, 4] 8,192
Channel_Att-15 [[1, 2048, 4, 4]] [1, 2048, 4, 4] 0
Att-15 [[1, 2048, 4, 4]] [1, 2048, 4, 4] 0
BottleneckBlock-15 [[1, 2048, 4, 4]] [1, 2048, 4, 4] 0
Conv2D-51 [[1, 2048, 4, 4]] [1, 512, 4, 4] 1,048,576
BatchNorm2D-66 [[1, 512, 4, 4]] [1, 512, 4, 4] 2,048
ReLU-17 [[1, 2048, 4, 4]] [1, 2048, 4, 4] 0
Conv2D-52 [[1, 512, 4, 4]] [1, 512, 4, 4] 2,359,296
BatchNorm2D-67 [[1, 512, 4, 4]] [1, 512, 4, 4] 2,048
Conv2D-53 [[1, 512, 4, 4]] [1, 2048, 4, 4] 1,048,576
BatchNorm2D-68 [[1, 2048, 4, 4]] [1, 2048, 4, 4] 8,192
BatchNorm2D-69 [[1, 2048, 4, 4]] [1, 2048, 4, 4] 8,192
Channel_Att-16 [[1, 2048, 4, 4]] [1, 2048, 4, 4] 0
Att-16 [[1, 2048, 4, 4]] [1, 2048, 4, 4] 0
BottleneckBlock-16 [[1, 2048, 4, 4]] [1, 2048, 4, 4] 0
AdaptiveAvgPool2D-1 [[1, 2048, 4, 4]] [1, 2048, 1, 1] 0
Linear-1 [[1, 2048]] [1, 100] 204,900
===============================================================================
Total params: 23,818,788
Trainable params: 23,652,132
Non-trainable params: 166,656
-------------------------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 121.64
Params size (MB): 90.86
Estimated Total Size (MB): 212.51
-------------------------------------------------------------------------------
{'total_params': 23818788, 'trainable_params': 23652132}
class ToArray(object):
def __call__(self, img):
img = np.array(img)
img = np.transpose(img, [2, 0, 1])
img = img / 255.
return img.astype('float32')class RandomApply(object):
def __init__(self, transform, p=0.5):
super().__init__()
self.p = p
self.transform = transform
def __call__(self, img):
if self.p < random.random(): return img
img = self.transform(img) return img
class LRSchedulerM(callbacks.LRScheduler):
def __init__(self, by_step=False, by_epoch=True, warm_up=True):
super().__init__(by_step, by_epoch)  assert by_step ^ warm_up
self.warm_up = warm_up
def on_epoch_end(self, epoch, logs=None):
if self.by_epoch and not self.warm_up: if self.model._optimizer and hasattr(
self.model._optimizer, '_learning_rate') and isinstance(
self.model._optimizer._learning_rate, paddle.optimizer.lr.LRScheduler):
self.model._optimizer._learning_rate.step()
def on_train_batch_end(self, step, logs=None):
if self.by_step or self.warm_up:
if self.model._optimizer and hasattr(
self.model._optimizer, '_learning_rate') and isinstance(
self.model._optimizer._learning_rate, paddle.optimizer.lr.LRScheduler):
self.model._optimizer._learning_rate.step() if self.model._optimizer._learning_rate.last_epoch >= self.model._optimizer._learning_rate.warmup_steps:
self.warm_up = Falsedef _on_train_batch_end(self, step, logs=None):
logs = logs or {}
logs['lr'] = self.model._optimizer.get_lr()
self.train_step += 1
if self._is_write():
self._updates(logs, 'train')def _on_train_begin(self, logs=None):
self.epochs = self.params['epochs'] assert self.epochs
self.train_metrics = self.params['metrics'] + ['lr'] assert self.train_metrics
self._is_fit = True
self.train_step = 0callbacks.VisualDL.on_train_batch_end = _on_train_batch_end
callbacks.VisualDL.on_train_begin = _on_train_begin
assert by_step ^ warm_up
self.warm_up = warm_up
def on_epoch_end(self, epoch, logs=None):
if self.by_epoch and not self.warm_up: if self.model._optimizer and hasattr(
self.model._optimizer, '_learning_rate') and isinstance(
self.model._optimizer._learning_rate, paddle.optimizer.lr.LRScheduler):
self.model._optimizer._learning_rate.step()
def on_train_batch_end(self, step, logs=None):
if self.by_step or self.warm_up:
if self.model._optimizer and hasattr(
self.model._optimizer, '_learning_rate') and isinstance(
self.model._optimizer._learning_rate, paddle.optimizer.lr.LRScheduler):
self.model._optimizer._learning_rate.step() if self.model._optimizer._learning_rate.last_epoch >= self.model._optimizer._learning_rate.warmup_steps:
self.warm_up = Falsedef _on_train_batch_end(self, step, logs=None):
logs = logs or {}
logs['lr'] = self.model._optimizer.get_lr()
self.train_step += 1
if self._is_write():
self._updates(logs, 'train')def _on_train_begin(self, logs=None):
self.epochs = self.params['epochs'] assert self.epochs
self.train_metrics = self.params['metrics'] + ['lr'] assert self.train_metrics
self._is_fit = True
self.train_step = 0callbacks.VisualDL.on_train_batch_end = _on_train_batch_end
callbacks.VisualDL.on_train_begin = _on_train_begin
使用Paddle自带的Cifar100数据集API加载
In [ ]model = paddle.Model(resnet50(pretrained=False))# 加载checkpoint# model.load('output/ResNet50-NAM/299.pdparams')MAX_EPOCH = 300LR = 0.01WEIGHT_DECAY = 5e-4MOMENTUM = 0.9BATCH_SIZE = 256CIFAR_MEAN = [0.5071, 0.4865, 0.4409]
CIFAR_STD = [0.1942, 0.1918, 0.1958]
DATA_FILE = './data/data76994/cifar-100-python.tar.gz'model.prepare(
paddle.optimizer.Momentum(
learning_rate=LinearWarmup(CosineAnnealingDecay(LR, MAX_EPOCH), 2000, 0., LR),
momentum=MOMENTUM,
parameters=model.parameters(),
weight_decay=WEIGHT_DECAY),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy(topk=(1,5)))# 定义数据集增强方式transforms = Compose([
RandomCrop(32, padding=4),
RandomApply(BrightnessTransform(0.1)),
RandomApply(ContrastTransform(0.1)),
RandomHorizontalFlip(),
RandomRotation(15),
ToArray(),
Normalize(CIFAR_MEAN, CIFAR_STD),
])
val_transforms = Compose([ToArray(), Normalize(CIFAR_MEAN, CIFAR_STD)])# 加载训练和测试数据集train_set = Cifar100(DATA_FILE, mode='train', transform=transforms)
test_set = Cifar100(DATA_FILE, mode='test', transform=val_transforms)# 定义保存方式和训练可视化checkpoint_callback = paddle.callbacks.ModelCheckpoint(s*e_freq=1, s*e_dir='output/ResNet50-NAM')
callbacks = [LRSchedulerM(),checkpoint_callback, callbacks.VisualDL('vis_logs/resnet50_nam.log')]# 训练模型model.fit(
train_set,
test_set,
epochs=MAX_EPOCH,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4,
verbose=1,
callbacks=callbacks,
)
model = paddle.Model(paddle.vision.models.resnet50(pretrained=False))# 加载checkpoint# model.load('output/ResNet50-NAM/299.pdparams')MAX_EPOCH = 300LR = 0.01WEIGHT_DECAY = 5e-4MOMENTUM = 0.9BATCH_SIZE = 256CIFAR_MEAN = [0.5071, 0.4865, 0.4409]
CIFAR_STD = [0.1942, 0.1918, 0.1958]
DATA_FILE = './data/data76994/cifar-100-python.tar.gz'model.prepare(
paddle.optimizer.Momentum(
learning_rate=LinearWarmup(CosineAnnealingDecay(LR, MAX_EPOCH), 2000, 0., LR),
momentum=MOMENTUM,
parameters=model.parameters(),
weight_decay=WEIGHT_DECAY),
paddle.nn.CrossEntropyLoss(),
paddle.metric.Accuracy(topk=(1,5)))# 定义数据集增强方式transforms = Compose([
RandomCrop(32, padding=4),
RandomApply(BrightnessTransform(0.1)),
RandomApply(ContrastTransform(0.1)),
RandomHorizontalFlip(),
RandomRotation(15),
ToArray(),
Normalize(CIFAR_MEAN, CIFAR_STD),
])
val_transforms = Compose([ToArray(), Normalize(CIFAR_MEAN, CIFAR_STD)])# 加载训练和测试数据集train_set = Cifar100(DATA_FILE, mode='train', transform=transforms)
test_set = Cifar100(DATA_FILE, mode='test', transform=val_transforms)# 定义保存方式和训练可视化checkpoint_callback = paddle.callbacks.ModelCheckpoint(s*e_freq=1, s*e_dir='output/ResNet50')
callbacks = [LRSchedulerM(),checkpoint_callback, callbacks.VisualDL('vis_logs/resnet50.log')]# 训练模型model.fit(
train_set,
test_set,
epochs=MAX_EPOCH,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=4,
verbose=1,
callbacks=callbacks,
)
两次实验均使用相同的参数:
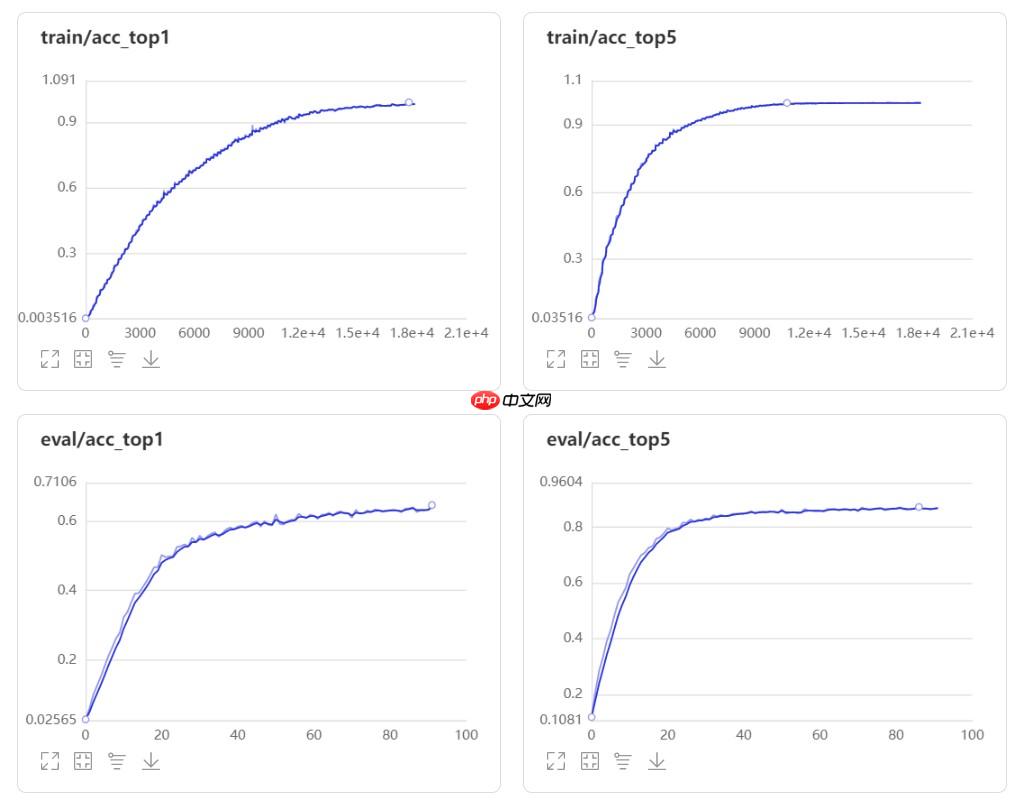
ResNet50-NAM模型的Top-1 acc和Top-5 acc如下图所示:
ResNet50模型的Top-1 acc和Top-5 acc如下图所示:
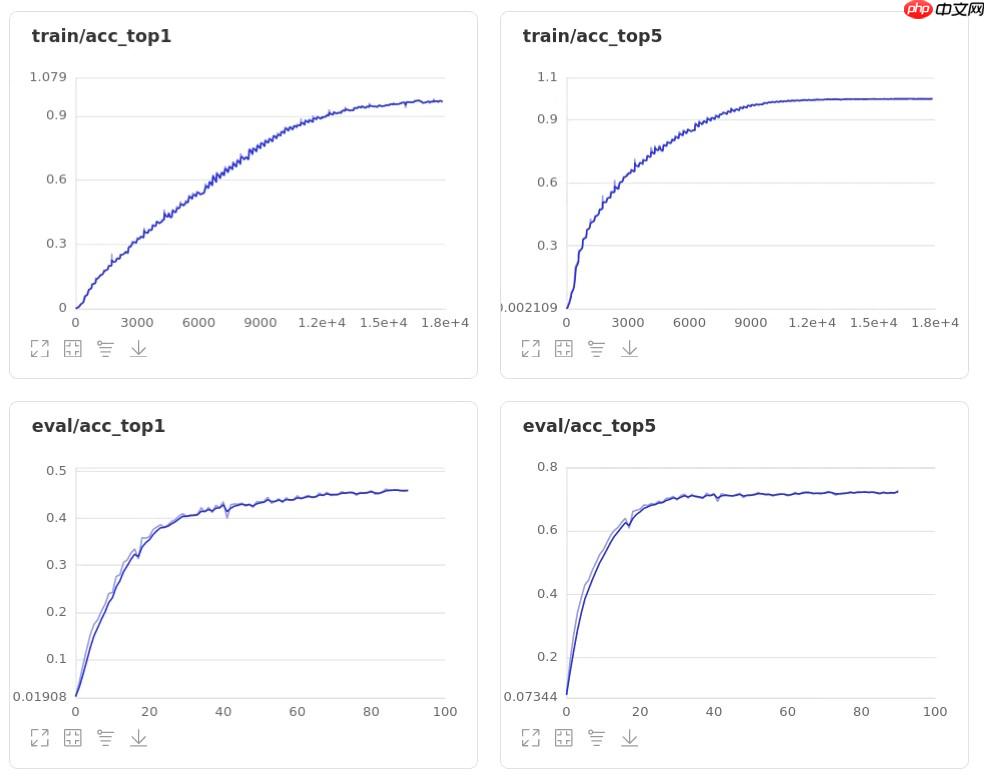
通过比较,经过修改后的模型效果得到了明显的提升,且原始ResNet50产生了明显的过拟合现象
models = paddle.Model(resnet50())
models.load('output/ResNet50-NAM/1.pdparams')
models.prepare()
result = models.evaluate(test_set, verbose=1)print(result)
以上就是【AI达人特训营】ResNet50-NAM:一种新的注意力计算方式复现的详细内容,更多请关注其它相关文章!
# git
# ai
# cos
# 为什么
# asic
# python
# 如下图
# 桐城网站优化哪家好点啊
# 凤岗视频营销推广
# 读书网站建设文案
# 自助网站建设全包
# 无锡抖音产品营销推广
# 临沂加盟网站维护推广
# 品牌营销推广费用计算表
# 平山企业网站推广电话
# 关于seo的感悟
# 重庆商家推广营销平台
# 官网
# 越大
# 如图
# 第一层
# 加载
# 一言
# 所示
# 达人
# 中文网
# type
# latte
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
国网辉南供电:无人机空中巡检 全力护航端午佳节
英伟达H100霸榜权威AI性能测试 11分钟搞定基于GPT-3的大模型训练
人工智能产业竞跑“未来赛道” 创新发展放大“赋能”效应
成功孵化首个大型模型解决方案的重庆人工智能创新中心
微软在 Bing 和 Edge 浏览器中拓展网购服务,帮用户选购心仪产品
“思享荟”沙龙热议AIGC与元宇宙 复旦大学赵星畅谈深度数字化
谷歌计划在上海举办开发者大会,重点关注机器学习和生成式AI领域
郭帆导演成功利用AI技术制作的《流浪地球3》预告片在央视热播,引发巨大反响
OpenAI 为开发者推出 GPT 聊天机器人 API 大更新,同时降低价格
网友自制 AI 版《流浪地球 3》预告片,登上 CCTV6
RoboNeo安装教程
甲骨文与Cohere合作为企业提供生成式人工智能服务
美图影像节演讲实录:191次提及AI,发布7款影像生产力工具
全面拥抱大模型浪潮,ISC 2025打造全球首场AI数字安全峰会
当孔子遇见AI|尼山的“数字”
CREATOR制造、使用工具,实现LLM「自我进化」
AI 程序 Text With Jesus 在海外迅速受到关注:与耶稣和撒旦进行对话
杭州举办第19届亚运会,主题为「亚运元宇宙」的发布仪式举行
Unity 推出面向开发者的 AI 软件市场 AI Hub,股价飙涨 15%
腾讯AI首次模拟拼接三星堆文物,工作取得阶段性的成果
中国联通推出“极光一号”5G机载终端,适配大疆等品牌无人机设备
为什么很多人对纽约《人工智能招聘法》感到生气?
懒人必备的家居清洁好物,石头自清洁扫拖机器人G20
探索人工智能在物联网领域的影响与改变
报告称 70% 程序员已使用各种 AI 工具编程
第二届光合组织AI解决方案大赛赛果揭晓
英伟达推出 L40S GPU,AI 推理性能超过 A100 约 1.2 倍
AI和ML推动联网设备的增长
AI+游戏首度大范围公布实际应用成果,AI全面来临还有多远?
上新7款产品,美图继续“蹭”AI
应对算力挑战,亚马逊云科技发力AI基础设施建设
探展WAIC |万向区块链杜宇:不存在单一技术的iPhone时刻,Web3.0核心将基于AI+区块链+物联网
“世界上最像人的机器人”接入 Stable Diffusion ,现场完成作画
当科幻走进现实 脑机接口新技术能为生活带来哪些惊喜?
当一个网站的内容被 AI 完全接管
人工智能赋能无人驾驶:商业化进程再提速
类GPT模型训练提速26.5%,清华朱军等人用INT4算法加速神经网络训练
走进首家“元宇宙”未来工厂,卡奥斯探知工业之旅出发!
了解 AGI:智能的未来?
昌吉市利用无人机实现全天候河道动态巡检
多家欧洲企业签署公开信,批评欧盟 AI 法案草案限制产业发展
大疆 DJI Mini 4 Pro 无人机曝光:流线设计,有望迎来功能性提升
一文读懂自动驾驶的激光雷达与视觉融合感知
马斯克发推讽刺人工智能:机器学习的本质就是统计
机器人技能大比拼
联通发布鸿湖图文AI大模型1.0,可实现以文生图
650亿参数,8块GPU就能全参数微调:邱锡鹏团队把大模型门槛打下来了
联想创投携手12家被投企业MWC展示元宇宙、机器人等技术
特斯拉人形机器人将亮相 预计售价不超过15万元
OpenAI已向中国申请注册“GPT-5”商标,此前已在美国提交申请
 当前位置:
当前位置:  assert by_step ^ warm_up
self.warm_up = warm_up
def on_epoch_end(self, epoch, logs=None):
if self.by_epoch and not self.warm_up: if self.model._optimizer and hasattr(
self.model._optimizer, '_learning_rate') and isinstance(
self.model._optimizer._learning_rate, paddle.optimizer.lr.LRScheduler):
self.model._optimizer._learning_rate.step()
def on_train_batch_end(self, step, logs=None):
if self.by_step or self.warm_up:
if self.model._optimizer and hasattr(
self.model._optimizer, '_learning_rate') and isinstance(
self.model._optimizer._learning_rate, paddle.optimizer.lr.LRScheduler):
self.model._optimizer._learning_rate.step() if self.model._optimizer._learning_rate.last_epoch >= self.model._optimizer._learning_rate.warmup_steps:
self.warm_up = Falsedef _on_train_batch_end(self, step, logs=None):
logs = logs or {}
logs['lr'] = self.model._optimizer.get_lr()
self.train_step += 1
if self._is_write():
self._updates(logs, 'train')def _on_train_begin(self, logs=None):
self.epochs = self.params['epochs'] assert self.epochs
self.train_metrics = self.params['metrics'] + ['lr'] assert self.train_metrics
self._is_fit = True
self.train_step = 0callbacks.VisualDL.on_train_batch_end = _on_train_batch_end
callbacks.VisualDL.on_train_begin = _on_train_begin
assert by_step ^ warm_up
self.warm_up = warm_up
def on_epoch_end(self, epoch, logs=None):
if self.by_epoch and not self.warm_up: if self.model._optimizer and hasattr(
self.model._optimizer, '_learning_rate') and isinstance(
self.model._optimizer._learning_rate, paddle.optimizer.lr.LRScheduler):
self.model._optimizer._learning_rate.step()
def on_train_batch_end(self, step, logs=None):
if self.by_step or self.warm_up:
if self.model._optimizer and hasattr(
self.model._optimizer, '_learning_rate') and isinstance(
self.model._optimizer._learning_rate, paddle.optimizer.lr.LRScheduler):
self.model._optimizer._learning_rate.step() if self.model._optimizer._learning_rate.last_epoch >= self.model._optimizer._learning_rate.warmup_steps:
self.warm_up = Falsedef _on_train_batch_end(self, step, logs=None):
logs = logs or {}
logs['lr'] = self.model._optimizer.get_lr()
self.train_step += 1
if self._is_write():
self._updates(logs, 'train')def _on_train_begin(self, logs=None):
self.epochs = self.params['epochs'] assert self.epochs
self.train_metrics = self.params['metrics'] + ['lr'] assert self.train_metrics
self._is_fit = True
self.train_step = 0callbacks.VisualDL.on_train_batch_end = _on_train_batch_end
callbacks.VisualDL.on_train_begin = _on_train_begin 上一篇:
上一篇: 返回列表
返回列表