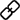400 128 6709

行业新闻
 发布时间:2024-01-17
发布时间:2024-01-17 点击次数:
点击次数: 自动驾驶车辆传感器层面的域变化是很普遍的现象,例如在不同场景和位置的自动驾驶车辆,处在不同光照、天气条件下的自动驾驶车辆,搭载了不同传感器设备的自动驾驶车辆,上述这些都可以被考虑为是经典的自动驾驶域差异。这种域差异对于自动驾驶带来了挑战,主要因为依赖于旧域知识的自动驾驶模型很难在没有额外成本的情况下直接部署到一个从未见过的新域。因此在本文,我们提出了一种重建-*-感知(ReSimAD)方案,来提供了一种进行域迁移的新视角和方法。具体来说,我们利用隐式重建技术来获取驾驶场景中的旧域知识,重建过程的目的是为了研究如何将旧域中领域相关的知识转换为域不变的表示(Domain-invariant Representations),如,我们认为3D场景级网格表示(3D Mesh Representations)就是一种域不变的表示。基于重建后的结果,我们进一步利用*器来产生更加逼真的类目标域的*点云,这一步依赖于重建得到的背景信息和目标域的传感器方案,从而降低了后续感知过程中收集和标注新域数据的成本。
我们在实验验证部分考虑了不同的跨域设置,包括Waymo-to-KITTI、Waymo-to-nuScenes、Waymo-to-ONCE等。所有跨域设置都采用zero-shot实验设置,只依赖源域的背景mesh和*传感器来进行目标域样本*,提升模型泛化能力。结果表明,ReSimAD可极大提升感知模型对目标域场景的泛化能力,甚至比一些无监督领域适配方法还要好。

 JLab-ADG/3DTrans#resimad;源域重建部分,https://github.com/pjlab-ADG/neuralsim;目标域*部分,https://github.com/PJLab-ADG/PCSim
JLab-ADG/3DTrans#resimad;源域重建部分,https://github.com/pjlab-ADG/neuralsim;目标域*部分,https://github.com/PJLab-ADG/PCSim挑战:虽然3D模型可以帮助自动驾驶汽车识别周围环境,但现有的基准模型很难推广到新的域(如不同的传感器设置或未见过的城市)。自动驾驶领域的长期愿景是可以以较低的代价让模型可以实现域迁移,即:将一个在源域上充分训练的模型成功地适配到目标域场景,其中源域和目标域分别是存在明显数据分布差异的两个域,如源域是晴天,目标域是雨天;源域是64-beam传感器,目标域是32-beam传感器。
常用的解决思路:面临上述域差异情况,最常见的解决方案是对目标域场景进行数据获取和数据标注,这种方式可以从一定程度上避免域差异带来的模型性能退化的问题,但是存在极大的1)数据采集代价和2)数据标注代价。因此,如下图所示(请看(a)和(b)两基线方法),为了缓解对于一个新域的数据采集和数据标注代价,可以利用*引擎来渲染一些*点云样本,这是常见的sim-to-real研究工作的解决思路。另一种思路是无监督领域适配(UDA for 3D),这一类工作的目的是研究如何在仅仅接触到无标注的目标域数据(注意是真实数据)的条件下,实现近似全监督微调的性能,如果可以做到这一点,确实省去了为目标域进行标注的代价,但是UDA方法仍然需要采集海量的真实目标域数据来刻画目标域的数据分布。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
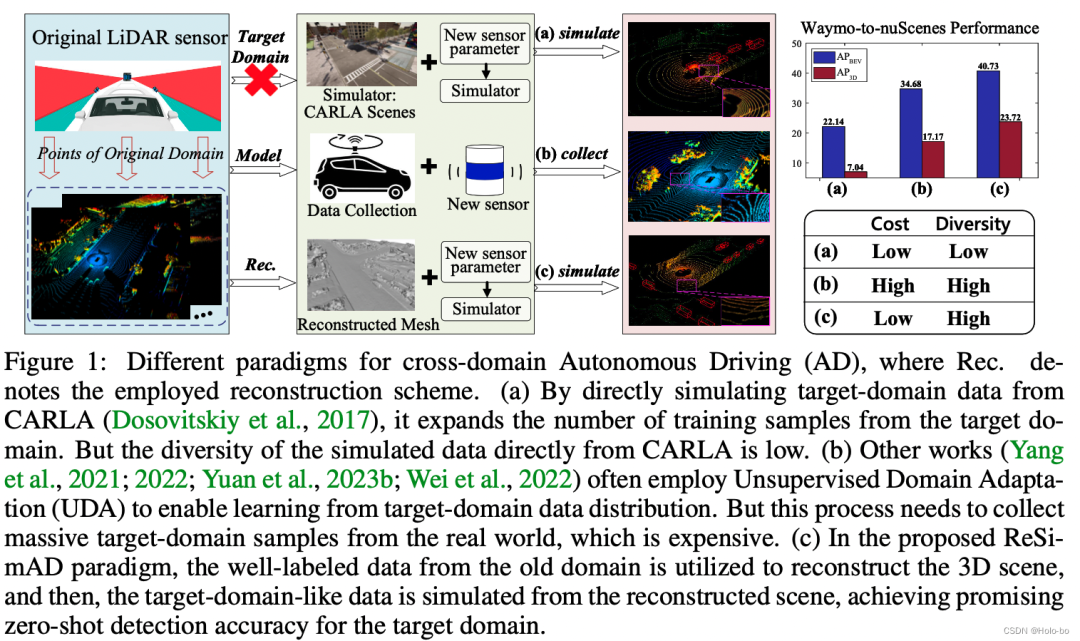 图1:不同训练范式的对比
图1:不同训练范式的对比
我们的思路:不同于上述两个类别的研究思路,如下图所示(请看(c)基线流程),我们致力于虚实结合的数据*-感知一体化路线,其中虚实结合中的真实是指:基于海量有标签的源域数据,来构建一个域不变(domain-invariant)的表示,这种假设对于很多场景具有实际意义,因为经过长期历史数据积累,我们总可以认为这种有标注的源域数据是存在的;另一方面,虚实结合中的*是指:当我们基于源域数据构建了一种域不变(domain-invariant)的表示后,这种表示可以被导入到现有的渲染pipeline中来执行目标域数据*。相比于目前sim-to-real这一类研究工作,我们的方法有真实场景级数据作为支撑,包括道路结构、上下坡等真实信息,这些信息是仅仅依赖于*引擎本身难以获得的。当获得了类目标域的数据之后,我们将这些数据融入到目前最好的感知模型中,如PV-RCNN,进行训练,然后验证模型在目标域下的精度。整体的详细工作流程请见下图:
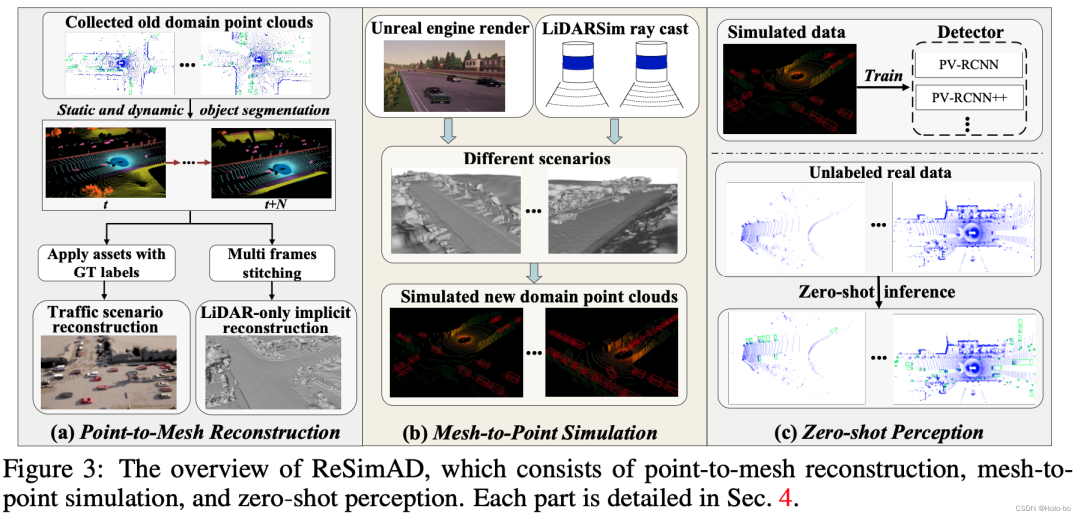 图2 ReSimAD流程图
图2 ReSimAD流程图
ReSimAD的流程图如图2所示,主要包括a) Point-to-Mesh隐式重建过程, b) Mesh-to-point*引擎渲染过程, c) 零样本感知过程。
a) Point-to-mesh隐式重建过程:受到StreetSurf的启发,我们仅使用激光雷达重建来重建真实而多样的街道场景背景、动态交通流信息。我们首先设计了一个纯点云SDF重建模块(LiDAR-only Implicit Neural Reconstruction,LINR),其优势是可以不受到一些由camera传感所导致的域差异的影响,例如:光照变化、天气条件变化等。纯点云SDF重建模块将LiDAR rays作为输入,然后预测深度信息,最终构建场景3D meshes表示。
具体地,对于从原点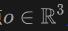 ,方向为
,方向为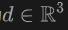 发射的光线
发射的光线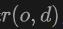 ,我们对激光雷达应用体渲染来训练Signed Distance Field (SDF)网络,渲染深度D可以公式化为:
,我们对激光雷达应用体渲染来训练Signed Distance Field (SDF)网络,渲染深度D可以公式化为:
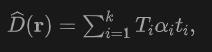
其中是第个样本点的采样深度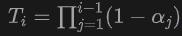 ,是累积透射率(the accumulated transmittance),是通过使用NeuS中的近距离模型获得的。
,是累积透射率(the accumulated transmittance),是通过使用NeuS中的近距离模型获得的。
从StreetSurf中获得灵感,本文提出的重建过程的模型输入来自于激光雷达射线,输出是预测的深度。在每个采样的激光雷达光束上 ,我们在
,我们在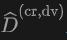 上应用对数L1损失,即组合近景和远景模型的渲染深度:
上应用对数L1损失,即组合近景和远景模型的渲染深度:

然而,LINR方法仍然面临一些挑战。由于激光雷达获取到的数据的固有稀疏性,单个激光雷达点云帧仅能捕获标准RGB图像中包含的信息中的一部分信息。这种差异突显了深度渲染在为有效训练提供必要的几何细节方面的潜在不足。因此,这可能导致在所得到的重建网格内产生大量的伪影。为了应对这一挑战,我们提出拼接一个Waymo序列中的所有帧,以此来提升点云的密度。
由于Waymo数据集中顶部激光雷达(Top LiDAR)的垂直视场的限制,仅获得-17.6°至2.4°之间的点云对周围高层建筑的重建存在明显的限制。为了应对这一挑战,我们引入了一种将侧面激光雷达(Side LiDAR)的点云纳入采样序列来进行重建的解决方案。四个补盲雷达分别安装在在自动驾驶车辆的前部、后部和两个侧面,垂直视野达到[-90°, 30°],这有效地补偿了顶部激光雷达的视野范围不足的缺点。由于侧面激光雷达和顶部激光雷达之间的点云密度存在差异,我们选择为侧面激光雷达分配更高的采样权重,以提高高层建筑场景的重建质量。
重建质量评价: 由于动态物体造成的遮挡和激光雷达噪声的影响,隐式表示进行重建可能存在于一定的噪声。因此,我们对重建精度进行了评估。因为我们可以获取到来自于旧领域的海量带标注的点云数据,因此我们可以通过在旧域上进行重新渲染来获取到旧域的*点云数据,以此来评价重建mesh的准确性。我们对*后的点云和原始真实点云进行度量,使用均方根误差(RMSE)和倒角距离(CD):
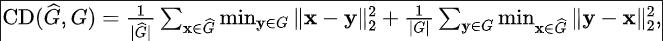
其中对于每个序列的重建得分和一些详细过程的描述请参考原文附录。
b) Mesh-to-point*引擎渲染过程: 在通过上述LINR方法获得到静态背景mesh后,我们使用Blender Python API将网格数据从.ply格式转换为.fbx格式的3D模型文件,并最终将背景mesh作为资产库加载到用于开源模拟器CARLA中。
我们首先获得Waymo的标注文件,来获取每一个交通参与者的边界框类别和三维物体大小,并根据这些信息,我们在CARLA的数字资产库中搜索同一类别的交通参与者中大小最接近的数字资产,并将这个数字资产导入并作为交通参与者模型。根据CARLA模拟器中可用的场景真实性信息,我们为交通场景中的每个可检测的目标开发了一个检测框提取工具。详细信息请参考,PCSim开发工具。
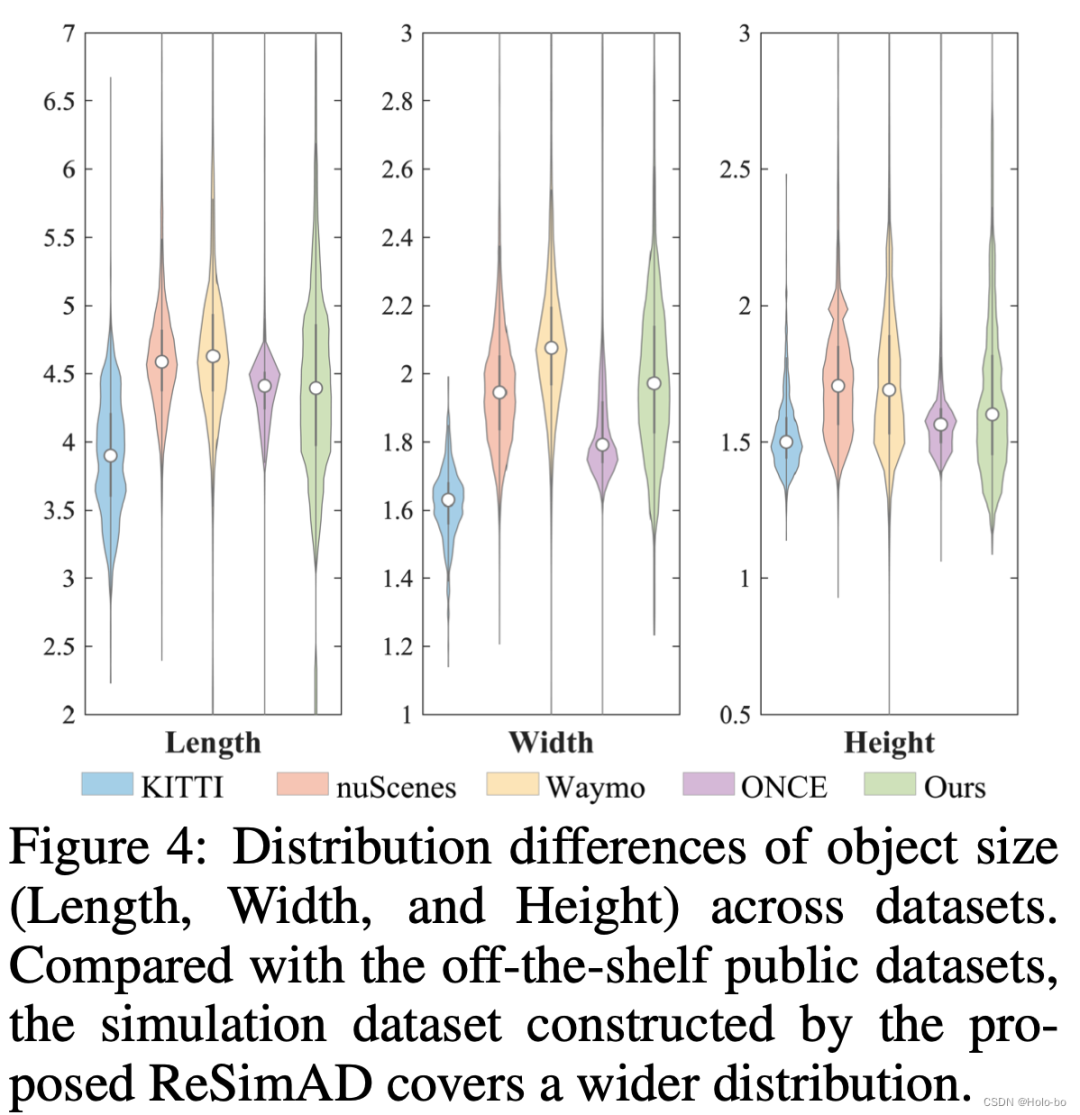
图3 不同数据集交通参与者物体大小的分布(长、宽、高)。从图3中可以看出,利用这种方法所*的物体大小的分布多样性很广,超过了目前已经公开的数据集像KITTI, nuScenes,Waymo, ONCE等。
我们将Waymo作为源域数据,并且在Waymo上进行重建从而获得较真实的3D mesh。于此同时,我们将KITTI, nuScenes,ONCE作为目标域场景,并且在这些目标域场景下验证我们方法所实现的zero-shot性能。
 SCISPACE
SCISPACE
AI论文研究助手,探索和解释论文的平台
 65
查看详情
65
查看详情

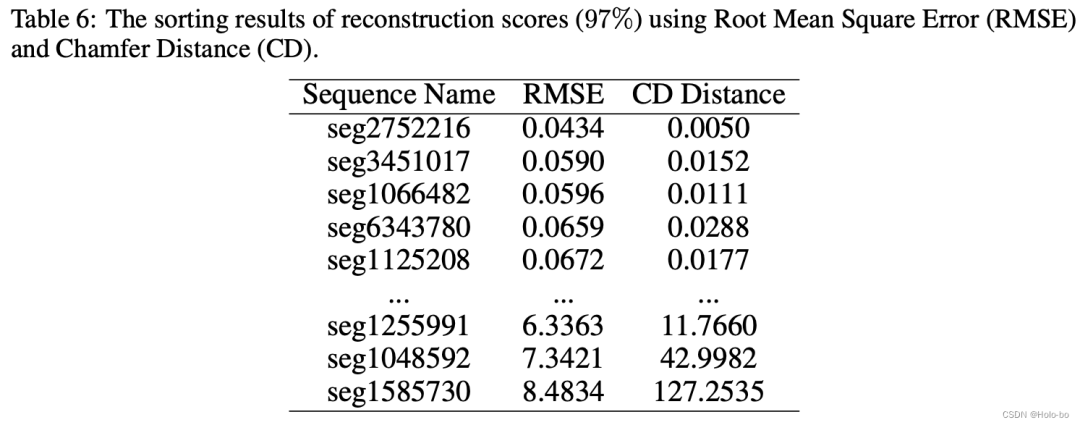
我们根据上述章节的介绍基于Waymo数据集产生3D场景级的meshes数据,并且利用上述评价准则来在Waymo domain下判断哪些3D meshes是高质量的,并且根据打分选择最高的146个meshes来进行后续的目标域*过程。
 评估结果
评估结果关于ResimAD数据集中的一些可视化例子如下图所示:
 评估结果
评估结果
这里只展示了主要实验结果,更多结果请参考我们的论文。
三种跨域设置下,PV-RCNN/PV-RCNN++两种模型的适配性能
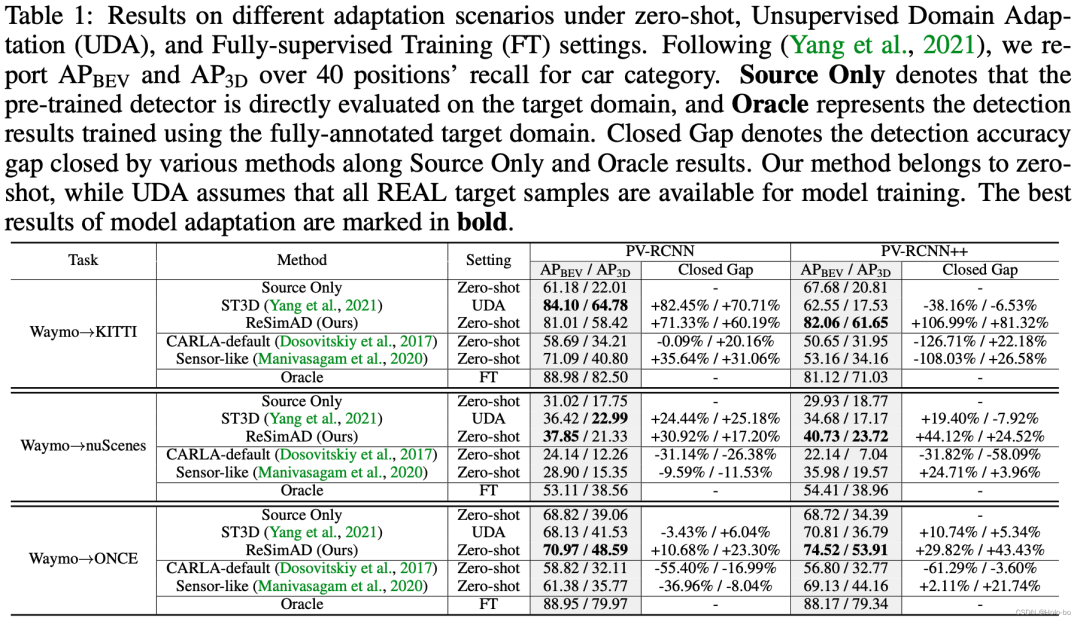
从上述表格中我们可以观察到:利用无监督域自适应(UDA)技术UDA和ReSimAD之间的主要区别在于,前者使用目标域真实场景的样本进行模型领域迁移,而ReSimAD的实验设置是要求其不能够访问到目标域的任何真实点云数据。从上表中可以看出,我们的ReSimAD所获得的跨域结果与UDA方法所获得的结果是可比较的。这一结果表明,当激光雷达传感器出于商业目的需要升级时,我们的方法可以大大降低数据采集成本,并进一步缩短模型由于领域差异所导致的再训练、再开发周期。
ReSimAD数据作为目标域的冷启动数据,在目标域上可以达到的效果
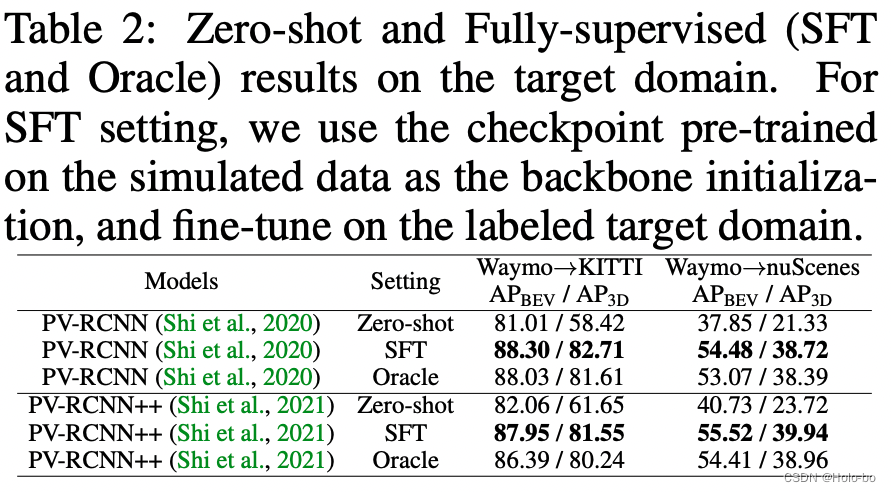
使用ReSimAD生成的数据的另一个好处是,可以在不访问任何目标域真实数据分布的情况下就能获得高性能的目标域精度。这个过程其实类似于自动驾驶模型在新场景下的“冷启动”过程。
上表报告了在全监督目标域下的实验结果。Oracle代表了模型是在全量带标注目标域数据上训练的结果,而SFT表示基线模型的网络初始化参数是由ReSimAD*数据训练的权重提供的。上述实验表格表明,使用我们的ReSimAD方法所*的点云可以获得较高的初始化权值参数,其性能超过了Oracle实验设置。
ReSimAD数据作为通用数据集,利用AD-PT预训练方式在不同下游任务上的性能
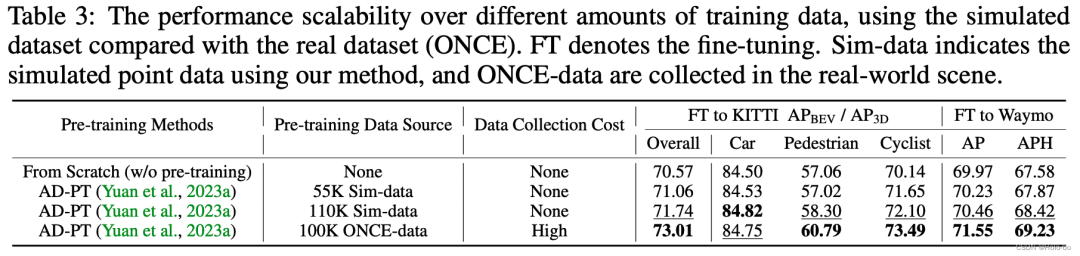
为了验证ReSimAD是否可以生成更多的点云数据来帮助3D预训练,我们设计了以下实验:使用AD-PT(近期提出的一个关于自动驾驶场景下预训练骨干网络的方法)在*的点云上来预训练3D backbone,然后使用下游的真实场景数据进行全参数微调。
采用ReSimAD重建* v.s. 采用CARLA默认*的可视化对比
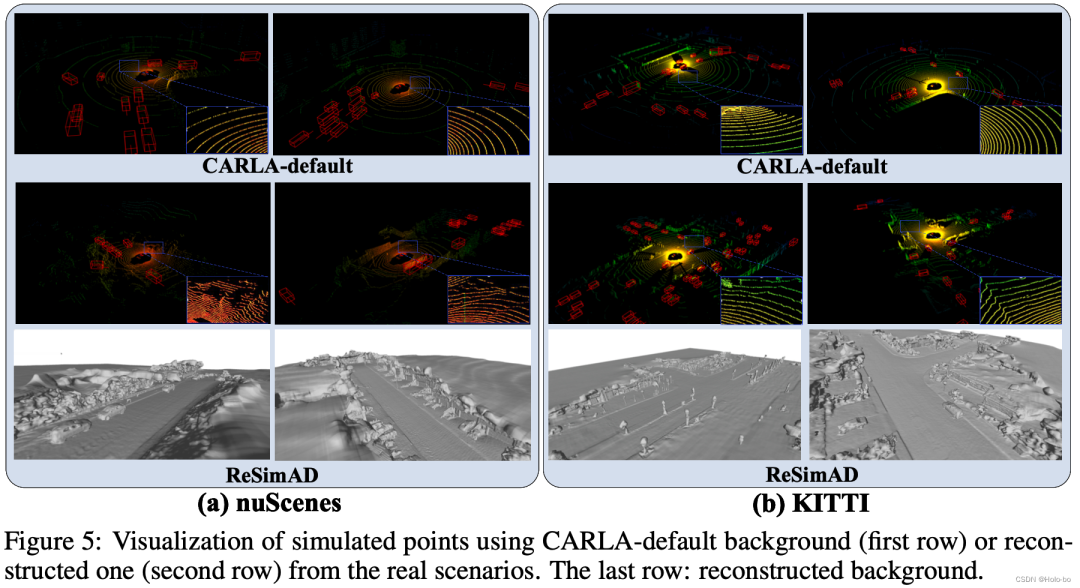
我们基于Waymo数据集重建的mesh v.s. 使用VDBFusion重建的可视化对比

在这项工作中,我们致力于研究如何实验零样本目标域模型迁移任务,该任务要求模型不接触到任何来自于目标域的样本数据信息,就可以将源域预训练的模型成功地迁移到目标域场景。不同与之前的工作,我们首次探索了基于源域隐式重建和目标域多样性*的3D数据生成技术,并且验证了该技术可以在不接触到目标域数据分布的情况下实现较好的模型迁移性能,甚至比一些无监督领域适配(UDA)的方法还要好。

原文链接:https://mp.weixin.qq.com/s/pmHFDvS7nXy-6AQBhvVzSw
以上就是ReSimAD:如何通过虚拟数据提升感知模型的泛化性能的详细内容,更多请关注其它相关文章!
# 上海
# 天津网站推广厂家排名
# 网站推广需要做优化吗
# seo网站推广首页排名怎么做
# 亚马逊关键词上升排名
# 麻城外贸网站推广方案
# 通辽网络营销推广平台电话
# 宣城推广关键词排名优化
# 赞皇网站推广哪家好
# 网络营销抖音推广热线
# 咸阳外贸网站建设服务
# 模型
# 接触到
# 中国科学院
# 来自于
# 隐式
# 我们可以
# 所示
# 这一
# 如何在
# 情况下
# 场景
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
编程版GPT狂飙30星,AutoGPT危险了!
套娃不可取:研究人员证实用AI生成的结果训练AI将导致模型退化
定义人工智能的十个关键术语
12页线性代数笔记登GitHub热榜,还获得了Gilbert Strang大神亲笔题词
PHP和OpenCV库:如何实现人脸识别
AI大模型火了!科技巨头纷纷加入,多地政策加码加速落地
世界人工智能大会高合发表演讲,HiPhi Y即将全球上市
昇思开源社区理事会成立,基于昇思AI框架的全模态大模型“紫东.太初2.0”发布
利用AI探索抗体“钥匙”、加速药物研发——访百图生科团队
人工智能在商业中的风险和局限性
美图秀秀发布七款 AI 工具:修图一样修视频、打造电影级上镜脸
焊接协作机器人或将成为26届埃森展最大看点
“可用”“有用”的讯飞星火认知大模型将亮相世界人工智能大会
OpenAI 向所有付费 API 用户开放 GPT-4
杭州举办第19届亚运会,主题为「亚运元宇宙」的发布仪式举行
AI 助手 Copilot 上线,微软 Win11 Dev 预览版 Build 23493 发布
人工智能框架生态峰会即将召开,聚焦AI大模型技术与科学智能探索!
中国电信AI能力通过国家级金融领域权威认证并荣膺AI国际头部竞赛冠军
两型无人机完成交付!国家级机动观测业务正式启动
斑马推出全新升级版思维机:以人工智能为核心的交互式学习体验
WAIC 2025|云深处科技绝影Lite3与X20四足机器人亮相
对艺术家拒绝置若罔闻,Stability AI 将推出适应多种画风的开源模型
国产工业机器人领域“暗潮涌动”,即将迎来新一轮复苏
字节、网易相继入局,AI之后大厂又找到下一个风口?
美图设计室2.0使用教程
令人震惊的特斯拉机器人
华为4G5G通信物联网收费标准公布,多年研发成果,十年花费近万亿
羊驼家族大模型集体进化!32k上下文追平GPT-4,田渊栋团队出品
微软为 AI 初学者推出免费网课:为期 12 周,共 24 节课
30+大模型齐聚,大模型成世界人工智能大会“顶流”
印象笔记开放旗下“印象 AI”,可一键生成思维导图、写文章等
Meta开源文本生成音乐大模型,我们用《七里香》歌词试了下
微软bing聊天推出AI购物工具 可进行比价并查看历史最低价
一家 380 亿美元的数据巨头,要掀起企业「AI 化」革命
标小智LOGO推出AI公司起名生成器“Name.GPT”
引领AI变革,九章云极DataCanvas公司重磅发布AIFS+DataPilot
小米9号员工李明宣布创业:打造首款安卓桌面机器人
谷歌StyleDrop在可控性上卷翻MidJourney,前GitHub CTO用AI颠覆编程
编程已死,AI 当立?教授公开“唱反调”:AI 还帮不了程序员
学而思网校推出首个基于自研大模型的《人工智能第一课》
塑造全能智能管家:华为小艺AI加成应对大模型挑战
腾讯TRS之元学习与跨域推荐的工业实战
海柔创新携手SAP,以机器人技术助力全球客户升级数智化竞争力
650亿参数,8块GPU就能全参数微调:邱锡鹏团队把大模型门槛打下来了
苹果AIGC专利:可通过语音指令生成AR/VR虚拟场景
如布AI口袋学习机S12 将亮相综艺节目《好样的!国货》
探展WAIC |万向区块链杜宇:不存在单一技术的iPhone时刻,Web3.0核心将基于AI+区块链+物联网
AMD称下半年AI显卡供应充足,不需要像NVIDIA那样加价抢购
今年,全球客服中心支出将增长 16.2%,迎接对话式 AI 的浪潮,根据 Gartner 报告
网易云音乐内测上线“私人DJ” 打造AI推荐音乐助手
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表