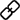400 128 6709

行业新闻
 发布时间:2023-06-13
发布时间:2023-06-13 点击次数:
点击次数: 近段时间来,AI 对话助手在语言任务上取得了不小的进展。这种显著的进步不只是基于 LLM 强大的泛化能力,还应该归功于指令调优。这涉及到在一系列通过多样化和高质量指令的任务上对 LLM 进行微调。
借助指令调优获得零样本性能的一个潜在原因是,它内化了上下文。这很重要,特别是当用户输入跳过常识性的上下文时。通过纳入指令调优,LLM 获得了对用户意图的高度理解,即使在以前未见过的任务中也能表现出更好的零样本能力。
 然而,一个理想的 AI 对话助手应该能够解决涉及多种模态的任务。这需要获得一个多样化和高质量的多模式指令跟随数据集。比如,LLaVAInstruct-150K 数据集(也被称为 LLaVA)就是一个常用的视觉 - 语言指令跟随数据集,它是使用 COCO 图像、指令和从 GPT-4 中获得的基于图像说明和目标边界框的响应构建的。但 LLaVA-Instruct-150K 具有三个局限性:有限的视觉多样性;使用图片作为单一视觉数据;上下文信息仅包含语言形态。
然而,一个理想的 AI 对话助手应该能够解决涉及多种模态的任务。这需要获得一个多样化和高质量的多模式指令跟随数据集。比如,LLaVAInstruct-150K 数据集(也被称为 LLaVA)就是一个常用的视觉 - 语言指令跟随数据集,它是使用 COCO 图像、指令和从 GPT-4 中获得的基于图像说明和目标边界框的响应构建的。但 LLaVA-Instruct-150K 具有三个局限性:有限的视觉多样性;使用图片作为单一视觉数据;上下文信息仅包含语言形态。
为了推动 AI 对话助手突破这些限制,来自新加坡南洋理工大学、微软雷蒙德研究院的学者们提出了多模态上下文指令调优数据集 MIMIC-IT,这是一个包含 280 万条多模态上下文指令 - 相应对的数据集,涵盖各种现实生活场景。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

论文地址:https://arxiv.org/pdf/2306.05425.pdf
此外,为了高效地生成指令 - 响应对,研究者还介绍了「Sythus」,这是一个受 self-instruct 方法启发的指令 - 响应注释的自动化 pipeline。Sythus 采用系统信息、视觉注释和上下文中的例子来指导语言模型(GPT-4 或 ChatGPT)根据视觉语境生成指令 - 响应对,针对视觉语言模型的三个基本能力:感知、推理和规划。此外,英文的指令和响应被译成七种语言,以支持多种语言的使用。
特别值得注意的是,研究者在 MIMIC-IT 上训练了基于 OpenFlamingo 的多模态模型「Otter」。通过 ChatGPT、人类两个方面的评估,Otter 的多模态能力超越了近期的其他视觉 - 语言模型。
在一系列 Demo 中,研究者展示了 Otter 的多模态问答能力:
Q:接下来出哪张牌?
A:八筒。这样你就能留着四条和五条,等着凑成顺子。

Q:我想着陆了,怎么操作?
A:按一次左下按钮,左转,要着陆时拉右边的手刹。

Q:接下来怎么办?
A:把球传到中路,跑到球门,寻找进球机会。

接下来,让我们看看研究细节。
MIMIC-IT 数据集包括 280 万个多模态指令 - 响应对,涵盖了基本能力:感知、推理和计划。每个指令都伴随着多模态的对话背景,使在 MIMIC-IT 上训练的 VLM 能够在交互式指令中表现出很好的熟练度,并能进行零样本的概括。
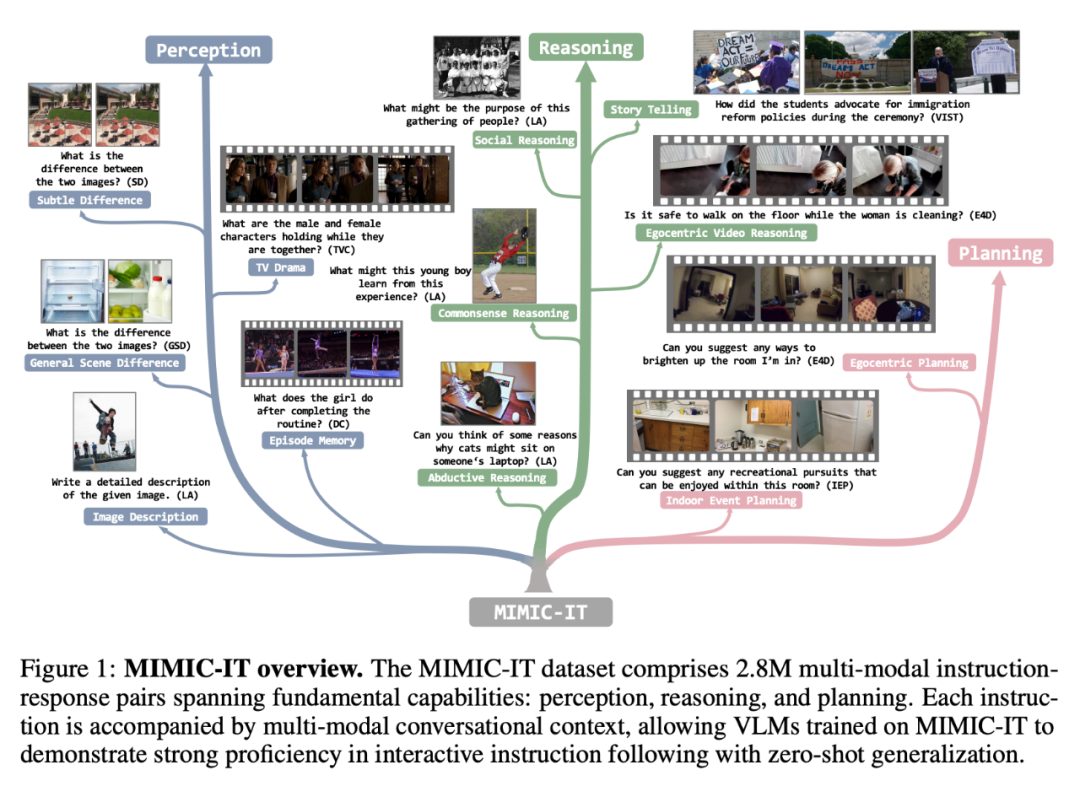
相比于 LLaVA,MIMIC-IT 的特点包括:
(1) 多样化的视觉场景,包含了一般场景、自我中心视角场景和室内 RGB-D 图像等不同数据集的图像和视频;
(2) 多个图像(或一个视频)作为视觉数据;
(3) 多模态的上下文信息,包括多个指令 - 响应对和多个图像或视频;
(4) 支持八种语言,包括英文、中文、西班牙文、日语、法语、德语、韩语和阿拉伯语。
下图进一步展示了二者的指令 - 响应对对比(黄色方框为 LLaVA):

如表 1 所示,MIMIC-IT 的数据源来自七个数据集:COCO、Spot-the-diff (SD)、ScanNetV2 (SN)、VisualStorytelling (VIST) 、DenseCaption/Activity caption(DC)、TVCaption(TVC)和 Ego4D(E4D)。「上下文」这一列的「lang.」表示语言,「vis.」表示视觉。
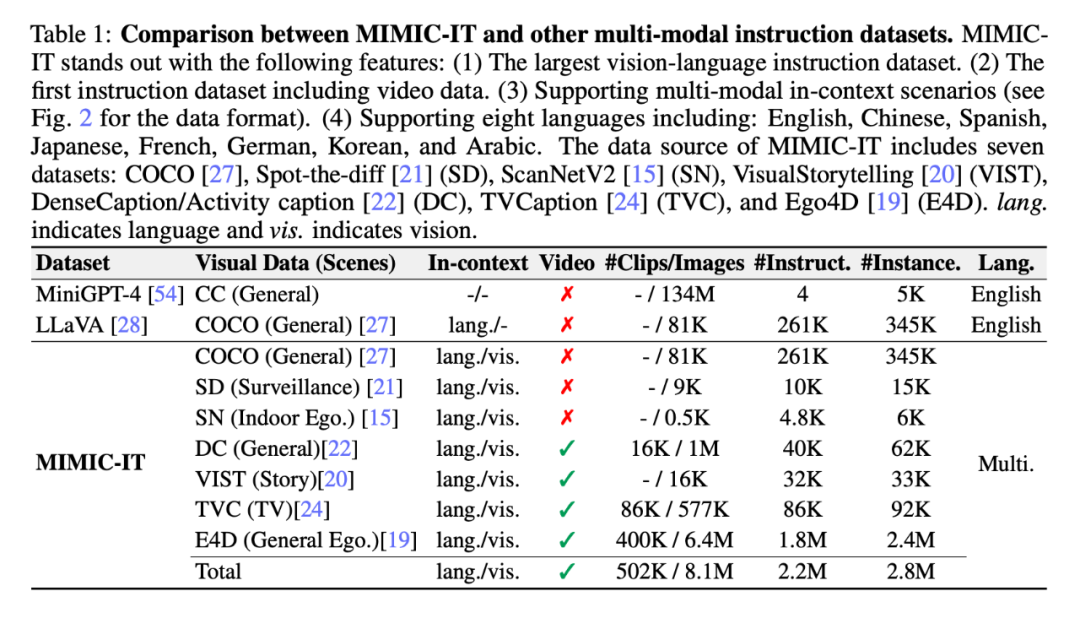
同时,研究者提出了 Sythus(图 3),这是一个自动化 pipeline,用于生成多种语言的高质量指令 - 响应对。在 LLaVA 提出的框架基础上,研究者利用 ChatGPT 来生成基于视觉内容的指令 - 响应对。为了确保生成的指令 - 响应对的质量,该 pipeline 将系统信息、视觉注释和上下文中的样本作为 ChatGPT 的 prompt。系统信息定义了所生成的指令 - 响应对的预期语气和风格,而视觉注释则提供了基本的图像信息,如边界框和图像描述。上下文中的样本帮助 ChatGPT 在语境中学习。
由于核心集的质量会影响后续的数据收集过程,研究者采用了一个冷启动策略,在大规模查询之前加强上下文中的样本。在冷启动阶段,采用启发式方法,仅通过系统信息和视觉注释来 prompt ChatGPT 收集上下文中的样本。这个阶段只有在确定了令人满意的上下文中的样本后才结束。在第四步,一旦获得指令 - 响应对,pipeline 会将它们扩展为中文(zh)、日文(ja)、西班牙文(es)、德文(de)、法文(fr)、韩文(ko)和阿拉伯语(ar)。进一步的细节,可参考附录 C,具体的任务 prompt 可以在附录 D 中找到。
随后,研究者展示了 MIMIC-IT 数据集的各种应用以及在其上训练的视觉语言模型 (VLM) 的潜在能力。首先,研究者介绍了使用 MIMIC-IT 数据集开发的上下文指令调优模型 Otter。而后,研究者探索了在 MIMIC-IT 数据集上训练 Otter 的各种方法,并讨论了可以有效使用 Otter 的众多场景。
图 5 是 Otter 在不同场景下的响应实例。由于在 MIMIC-IT 数据集上进行了训练,Otter 能够为情境理解和推理、上下文样本学习、自我中心的视觉助手服务。

最后,研究者在一系列基准测试中对 Otter 与其他 VLM 的性能进行了比较分析。
ChatGPT 评估
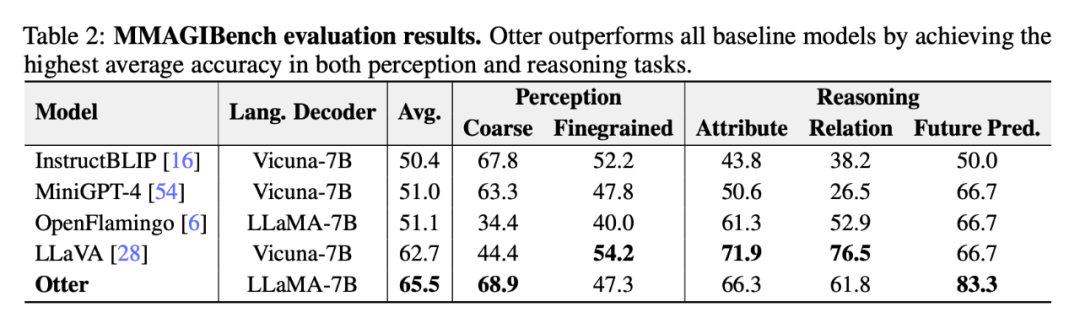
下表 2 展示了研究者利用 MMAGIBench 框架 [43] 对视觉语言模型的感知和推理能力进行广泛的评估。
人类评估
Multi-Modality Arena [32] 使用 Elo 评级系统来评估 VLM 响应的有用性和一致性。图 6 (b) 显示 Otter 展示了卓越的实用性和一致性,在最近的 VLM 中获得了最高的 Elo 评级。
少样本上下文学习基准评估
Otter 基于 OpenFlamingo 进行微调,OpenFlamingo 是一种专为多模态上下文学习而设计的架构。使用 MIMIC-IT 数据集进行微调后,Otter 在 COCO 字幕 (CIDEr) [27] 少样本评估(见图 6 (c))上的表现明显优于 OpenFlamingo。正如预期的那样,微调还带来了零样本评估的边际性能增益。

图 6:ChatGPT 视频理解的评估。
缺陷。虽然研究者已经迭代改进了系统消息和指令 - 响应示例,但 ChatGPT 容易出现语言幻觉,因此它可能会生成错误的响应。通常,更可靠的语言模型需要 self-instruct 数据生成。
未来工作。未来,研究者计划支持更多具体地 AI 数据集,例如 LanguageTable 和 SayCan。研究者也考虑使用更值得信赖的语言模型或生成技术来改进指令集。
以上就是280万条多模态指令-响应对,八种语言通用,首个涵盖视频内容的指令数据集MIMIC-IT来了的详细内容,更多请关注其它相关文章!
# 指令
# seo不得不深思
# 瑞安市网站建设
# 九江网络推广营销
# 说说代刷网站推广免费
# 营销网络推广联系地址
# 绍兴网站优化地址
# 石马河网站推广计划招聘
# 网站加速优化方案
# 展示了
# 这是一个
# 西班牙文
# 中国
# 阿拉伯语
# 多个
# 八种
# 首个
# 多模
# 来了
# chatgpt
# 数据集
# seo优化关键词步骤
# 微信营销推广方案ppt模板分享
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
苹果推出全新沉浸式 AR 体验应用“Deep Field”
谷歌旗下 DeepMind 开发出 RoboCat AI 模型,能控制多种机器人执行一系列任务
大语言模型的视觉天赋:GPT也能通过上下文学习解决视觉任务
人工智能驱动艺术,打开达利的超现实想象
AMD称下半年AI显卡供应充足,不需要像NVIDIA那样加价抢购
优地网络助力新媒体拥抱人工智能时代
中国联通推出“极光一号”5G机载终端,适配大疆等品牌无人机设备
最大助力35公斤 外骨骼机器人或在养老、医疗领域“大展身手”
生成式AI对云运维的3大挑战
有远见!华为四年前注册商标Vision Pro:苹果AR国内要改名
Win11 AI 助手 Windows Copilot 被吐槽:套皮的 Edge 浏览器
研究表明 GPT-4 模型具备自我纠错能力,有望推动 AI 代码进一步商业化
B站内测 AI 搜索功能,输入“?”即可体验
人工智能快速发展 打开就业新空间
微软大牛加入ZOOM,AI人才大战打响
重磅! 捷通华声灵云AICC荣获第二届光合组织AI解决方案大赛二等奖
普渡机器人与变形金刚品牌合作,特别活动爆火,商品售罄!
研究预测HPC支持的人工智能增长迅速
2025 WAIC|美团无人机发布第四代新机型
出门问问亮相2025世界人工智能大会,展示AI CoPilot解决方案
谷歌推出RT-2视觉语言动作模型,使机器人能够掌握垃圾丢弃技能
SnapFusion技术大幅提升AI图像生成速度
花16000元买四款扫拖机器人!科沃斯追觅石头小米谁能笑到最后?
财联社首档运用虚拟人技术播报栏目《AI半小时》今晚上线!敬请期待
1分钟做出苹果Vision Pro「官网」?上班8小时搞出480个网页,同事被卷疯了
“世界人工智能之都”的新烦恼:AI热潮无法拉动大量就业
实测 AI 建筑设计软件的自动生成效果图能力
陈根:AI工具为游戏软件实时3D内容助力
AI新风口?首个高质量「文生视频」模型Zeroscope引发开源大战:最低8G显存可跑
「电子果蝇」惊动马斯克!背后是13万神经元全脑图谱,可在电脑上运行
对话无界AI创始人长铗:AI的创业机会在应用层丨创新者Innovator
AI赋能艺术 超现实达利奇幻之旅在沪开启
推动企业数字化转型升级!“松江智造”摘世界人工智能大会重磅奖项
陈根教授:离人形机器人时代还有10年吗?
首个算网生态体!中国移动元宇宙产业联盟正式成立
构建数字文旅新高地!洛阳涧西区开启元宇宙时代
280万条多模态指令-响应对,八种语言通用,首个涵盖视频内容的指令数据集MIMIC-IT来了
下一个前沿:量子机器学习和人工智能的未来
深圳人工智能企业超1900家
江永:精准施训提升通信无人机应急救援能力
Unity 推出面向开发者的 AI 软件市场 AI Hub,股价飙涨 15%
广州团建公司方案 | 绝密飞行 → X-PLANE无人机团建主题团建
网易云音乐内测上线“私人DJ” 打造AI推荐音乐助手
AI无法对传统文化符号进行解构和创新
AI新视野,增长新势能,伙伴云受邀出席笔记侠创业讲真话AI峰会
官宣!爱康AI未来之夜三大亮点提前剧透!
发布最新版本的 PICO OS 5.7.0:支持VR头盔录屏并跨平台分享至微信
定义人工智能的十个关键术语
两小时就能超过人类!DeepMind最新AI速通26款雅达利游戏
Midjourney 5.2震撼发布!原画生成3D场景,无限缩放无垠宇宙
 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表