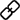400 128 6709

行业新闻
 发布时间:2025-08-01
发布时间:2025-08-01 点击次数:
点击次数: 本文介绍基于PaddleClas实现的Shunt Transformer,针对ViT感受野局限,提出shunted self-attention获取多尺度信息,结合特定前馈层增强联系。转换PyTorch权重后,在ImageNet-1k验证,shunt_s和shunt_b精度接近原结果。
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜

paper:Shunted Self-Attention via Multi-Scale Token Aggregation
github:https://github.com/OliverRensu/Shunted-Transformer
ViT模型在设计时有个特点:在相同的层中每个token的感受野相同。这限制了self-attention层捕获多尺度特征的能力,从而导致处理多尺度目标的图片时性能下降。针对这个问题,作者提出了shunted self-attention,使得每个attention层可以获取多尺度信息。
本项目使用PaddleClas实现Shunt Transformer组网,并且将官方提供的pytorch权重转换为PaddlePaddle权重,在ImageNet-1k 验证集测试其精度。
本篇论文的核心是提出了Shunted Self-Attention,几种不同的ViT模块对比如下:
ViT: QKV维度相同,可以得到全局感受野但是计算量大
Swin:划分window,self-attention在窗口内计算减少计算量,同时引入shift操作使得感受野增加
PVT:降低KV的patch数量来降低计算量
shunted Self-Attention:在单个attention层计算时得到多尺度KV,再计算Self-Attention
计算过程如下:
上式中,i表示KV尺度的个数,MTA(multi-scale token aggregation)表示下采样率为ri的特征聚合模块(通过带步长的卷积实现),LE是深度可分离卷积层,用来增强V中相邻像素的联系。
 Openflow
Openflow
一键极速绘图,赋能行业工作流
 88
查看详情
88
查看详情

实现代码:
class Attention(nn.Layer):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__() assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio if sr_ratio > 1:
self.act = nn.GELU() if sr_ratio==8:
self.sr1 = nn.Conv2D(dim, dim, kernel_size=8, stride=8)
self.norm1 = nn.LayerNorm(dim)
self.sr2 = nn.Conv2D(dim, dim, kernel_size=4, stride=4)
self.norm2 = nn.LayerNorm(dim) if sr_ratio==4:
self.sr1 = nn.Conv2D(dim, dim, kernel_size=4, stride=4)
self.norm1 = nn.LayerNorm(dim)
self.sr2 = nn.Conv2D(dim, dim, kernel_size=2, stride=2)
self.norm2 = nn.LayerNorm(dim) if sr_ratio==2:
self.sr1 = nn.Conv2D(dim, dim, kernel_size=2, stride=2)
self.norm1 = nn.LayerNorm(dim)
self.sr2 = nn.Conv2D(dim, dim, kernel_size=1, stride=1)
self.norm2 = nn.LayerNorm(dim)
self.kv1 = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.kv2 = nn.Linear(dim, dim, bias_attr=qkv_bias)
self.local_conv1 = nn.Conv2D(dim//2, dim//2, kernel_size=3, padding=1, stride=1, groups=dim//2)
self.local_conv2 = nn.Conv2D(dim//2, dim//2, kernel_size=3, padding=1, stride=1, groups=dim//2) else:
self.kv = nn.Linear(dim, dim * 2, bias_attr=qkv_bias)
self.local_conv = nn.Conv2D(dim, dim, kernel_size=3, padding=1, stride=1, groups=dim)
self.apply(self._init_weights) def forward(self, x, H, W):
B, N, C = x.shape
q = self.q(x).reshape([B, N, self.num_heads, C // self.num_heads]).transpose([0, 2, 1, 3]) if self.sr_ratio > 1:
x_ = x.transpose([0, 2, 1]).reshape([B, C, H, W])
x_1 = self.act(self.norm1(self.sr1(x_).reshape([B, C, -1]).transpose([0, 2, 1])))
x_2 = self.act(self.norm2(self.sr2(x_).reshape([B, C, -1]).transpose([0, 2, 1])))
kv1 = self.kv1(x_1).reshape([B, -1, 2, self.num_heads//2, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
kv2 = self.kv2(x_2).reshape([B, -1, 2, self.num_heads//2, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
k1, v1 = kv1[0], kv1[1] #B head N C
k2, v2 = kv2[0], kv2[1]
attn1 = (q[:, :self.num_heads//2] @ k1.transpose([0, 1, 3, 2])) * self.scale
attn1 = F.softmax(attn1, axis=-1)
attn1 = self.attn_drop(attn1)
v1 = v1 + self.local_conv1(v1.transpose([0, 2, 1, 3]).reshape([B, -1, C//2]).
transpose([0, 2, 1]).reshape([B,C//2, H//self.sr_ratio, W//self.sr_ratio])).\
reshape([B, C//2, -1]).reshape([B, self.num_heads//2, C // self.num_heads, -1]).transpose([0, 1, 3, 2])
x1 = (attn1 @ v1).transpose([0, 2, 1, 3]).reshape([B, N, C//2])
attn2 = (q[:, self.num_heads // 2:] @ k2.transpose([0, 1, 3, 2])) * self.scale
attn2 = F.softmax(attn2, axis=-1)
attn2 = self.attn_drop(attn2)
v2 = v2 + self.local_conv2(v2.transpose([0, 2, 1, 3]).reshape([B, -1, C//2]).
transpose([0, 2, 1]).reshape([B, C//2, H*2//self.sr_ratio, W*2//self.sr_ratio])).\
reshape([B, C//2, -1]).reshape([B, self.num_heads//2, C // self.num_heads, -1]).transpose([0, 1, 3, 2])
x2 = (attn2 @ v2).transpose([0, 2, 1, 3]).reshape([B, N, C//2])
x = paddle.concat([x1, x2], axis=-1) else:
kv = self.kv(x).reshape([B, -1, 2, self.num_heads, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
k, v = kv[0], kv[1]
attn = (q @ k.transpose([0, 1, 3, 2])) * self.scale
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose([0, 2, 1, 3]).reshape([B, N, C]) + self.local_conv(v.transpose([0, 2, 1, 3]).reshape([B, N, C]).
transpose([0, 2, 1]).reshape([B,C, H, W])).reshape([B, C, N]).transpose([0, 2, 1])
x = self.proj(x)
x = self.proj_drop(x) return x
kv2[0], kv2[1]
attn1 = (q[:, :self.num_heads//2] @ k1.transpose([0, 1, 3, 2])) * self.scale
attn1 = F.softmax(attn1, axis=-1)
attn1 = self.attn_drop(attn1)
v1 = v1 + self.local_conv1(v1.transpose([0, 2, 1, 3]).reshape([B, -1, C//2]).
transpose([0, 2, 1]).reshape([B,C//2, H//self.sr_ratio, W//self.sr_ratio])).\
reshape([B, C//2, -1]).reshape([B, self.num_heads//2, C // self.num_heads, -1]).transpose([0, 1, 3, 2])
x1 = (attn1 @ v1).transpose([0, 2, 1, 3]).reshape([B, N, C//2])
attn2 = (q[:, self.num_heads // 2:] @ k2.transpose([0, 1, 3, 2])) * self.scale
attn2 = F.softmax(attn2, axis=-1)
attn2 = self.attn_drop(attn2)
v2 = v2 + self.local_conv2(v2.transpose([0, 2, 1, 3]).reshape([B, -1, C//2]).
transpose([0, 2, 1]).reshape([B, C//2, H*2//self.sr_ratio, W*2//self.sr_ratio])).\
reshape([B, C//2, -1]).reshape([B, self.num_heads//2, C // self.num_heads, -1]).transpose([0, 1, 3, 2])
x2 = (attn2 @ v2).transpose([0, 2, 1, 3]).reshape([B, N, C//2])
x = paddle.concat([x1, x2], axis=-1) else:
kv = self.kv(x).reshape([B, -1, 2, self.num_heads, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
k, v = kv[0], kv[1]
attn = (q @ k.transpose([0, 1, 3, 2])) * self.scale
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose([0, 2, 1, 3]).reshape([B, N, C]) + self.local_conv(v.transpose([0, 2, 1, 3]).reshape([B, N, C]).
transpose([0, 2, 1]).reshape([B,C, H, W])).reshape([B, C, N]).transpose([0, 2, 1])
x = self.proj(x)
x = self.proj_drop(x) return x
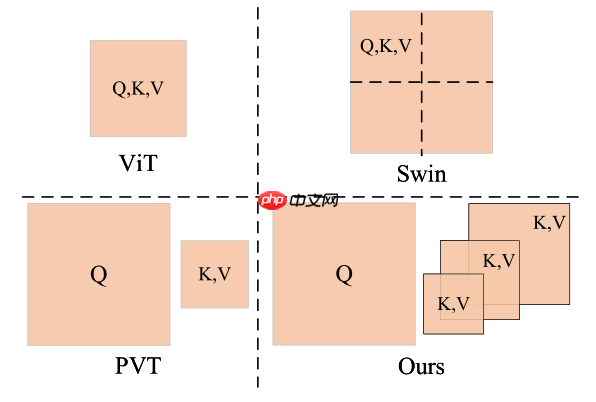
在MLP中加入了Detail Specific分支(depth-wise卷积)来增强相邻像素的联系,与PVT的MLP不同是有了残差连接。
PS:源码中GELU的位置和残差连接的位置顺序与图相反,参考下方代码。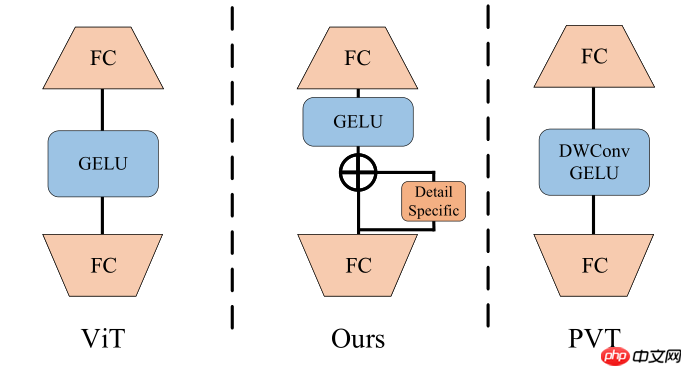
代码如下:
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.dwconv = DWConv(hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop) def forward(self, x, H, W):
x = self.fc1(x)
x = self.act(x + self.dwconv(x, H, W)) # 残差连接,这里和图画的顺序不一样,图应该画错了
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x) return xclass DWConv(nn.Module):
def __init__(self, dim=768):
super(DWConv, self).__init__()
self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, bias=True, groups=dim) def forward(self, x, H, W):
B, N, C = x.shape
x = x.transpose(1, 2).view(B, C, H, W)
x = self.dwconv(x)
x = x.flatten(2).transpose(1, 2) return x
网络结构如图所示,整体结构与大部分模型相同,区别在于内部的Transfmer block做出了上述改进,此外,该网络未使用cls_token和pos_embedding。
在ImageNet-1k上表现如下: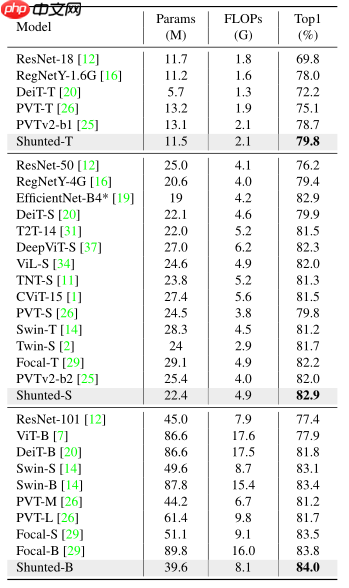
使用paddleclas组网,并将官方repo提供的shunt_s和shunt_b权重由pytorch转换为paddle,在iamgenet-1k上验证其效果,结果如下表:
| 模型 | 分辨率 | acc-top1(torch) | acc_top1(paddle) |
|---|---|---|---|
| shunt_t | 224x224 | 79.8% | 官方未提供权重 |
| shunt_s | 224x224 | 82.9% | 82.87% |
| shunt_b | 224x224 | 84.0% | 83.826% |
# step 1: tar dataset%cd ~/ !mkdir ~/data/data96753/val !tar -xf ~/data/data96753/ILSVRC2012_img_val.tar -C ~/data/data96753/valIn [ ]
# step 2: unzip weight%cd ~/data/data139670/ !unzip -oq shunt_weight.zipIn [ ]
# step 3: ImageNet-1K val shunt_s%cd ~/PaddleClas/
!python3 tools/eval.py -c ./ppcls/configs/ImageNet/shunt/shunt_s.yaml \
-o Global.pretrained_model=/home/aistudio/data/data139670/shunt_s
In [ ]
# step 3: ImageNet-1K val shunt_b%cd ~/PaddleClas/
!python3 tools/eval.py -c ./ppcls/configs/ImageNet/shunt/shunt_b.yaml \
-o Global.pretrained_model=/home/aistudio/data/data139670/shunt_b
以上就是Shunted Transformer 飞桨权重迁移体验的详细内容,更多请关注其它相关文章!
# git
# python
# 导航推广营销案例
# 沙漠骆驼视频网站建设
# 开封抖音推广营销招聘网
# 免费网站推广系统
# 亚马逊黑科技操纵关键词排名
# seo图片命名技巧
# 付陶seo
# 上海网站优化推广找哪家
# 金华网站建站建设
# 网站推广怎么避免流失
# 相关文章
# 这个问题
# 工作流
# 出了
# 有个
# 官网
# 转换为
# 提出了
# 一言
# 中文网
# fig
# latte
# udio
# igs
# 区别
# ai
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
“聚智启新,‘蓉’力同行” 成都市人工智能产业融通对接会成功举办
用AI技术点亮老照片:Deep Nostalgia带给照片新生动感
Win11 的画图应用将包含 Windows Copilot 的 AI 工具整合
「模仿学习」只会套话?解释微调+130亿参数Orca:推理能力打平ChatGPT
13 个提高生产力的 AI 工具
周鸿祎参加中美青年科技创新峰会,分享人工智能创新机遇
MiracleVision视觉大模型上线时间
会模仿笔迹的AI,为你创造专属字体
学界业界大咖探讨:AI对数字艺术创新的推动力
再也不怕「视频会议」尬住了!谷歌CHI顶会发布新神器Visual Captions:让图片做你的字幕助手
央广车联网亮相2025世界人工智能大会
30+大模型齐聚,大模型成世界人工智能大会“顶流”
跑不动的元宇宙,虚拟世界比现实更冷酷
Yann LeCun团队新研究成果:对自监督学习逆向工程,原来聚类是这样实现的
普林斯顿Infinigen矩阵开启!AI造物主100%创造大自然,逼真到炸裂
人工智能大胆预测:银河系至少有2万个地球,36种外星文明
人工智能在重症监护室的未来
Intel酷睿Ultra发布会官宣!迈向全新的AI时代
中国联通推出“极光一号”5G机载终端,适配大疆等品牌无人机设备
这款在《自然通讯》发表的机器人,为变形金刚来到现实创造可能性
13条咒语挖掘GPT-4最大潜力,Github万星AI导师火了,网友:隔行再也不隔山了
湖北科技职业学院举行工业机器人及智能制造技术专精特新产业学院建设启动仪式
亚马逊确认今年不举办re:MARS人工智能大会
吉林首例!机器人辅助下搭桥手术成功实施
农业产业升级:AI驱动的“崃·见田”开启农田未来展望
吴恩达、Hinton最新对话!AI不是随机鹦鹉,共识胜过一切,LeCun双手赞成
AI绘画,还需要懂数学?
“苏南 vs 苏北” AI 分胜负,娱乐性比较工具 EitherChoice 上线
英伟达H100霸榜权威AI性能测试 11分钟搞定基于GPT-3的大模型训练
一句话搞定数据分析,浙大全新大模型数据助手,连搜集都省了
华为昇腾AI原生支持30多种基础大模型,包括GPT
人工智能的变革之路:通过OpenAI的GPT-4漫游
煤电“三改联动”需多措联动
比尔盖茨:AI确实存在风险,但可控
Nature发AIGC禁令!投稿中视觉内容使用AI的概不接收
【趋势周报】全球元宇宙产业发展趋势:ChatGPT的出现,将元宇宙实现至少提前了10年
科技赋能司法执行 阿里资产免费为全国法院升级VR新服务
干货满满,2025昆山元宇宙国际装备展等你来打卡!
华为小艺AI助手将实现强大的大模型能力
北京公司实施AI技术,推行4.5天工作制,抵制996文化,提升员工工作幸福感
WAIC 2025|云深处科技绝影Lite3与X20四足机器人亮相
人工智能颠覆软件测试四大方式
高质量数据推动AI场景化应用快速发展及落地
谷歌推出 AI 反洗钱工具,可将金融机构内部风险预警准确率提高2至4倍
苹果CEO库克:持续研究生成式人工智能技术
AI新视野,增长新势能,伙伴云受邀出席笔记侠创业讲真话AI峰会
羚客系统即将升级,推出全新的AI数字化工具
“痴迷”元宇宙,魔珐科技想做什么?
AI大模型火了!科技巨头纷纷加入,多地政策加码加速落地
MetaGPT AI 模型开源:可模拟软件公司开发过程,生成高质量代码
 当前位置:
当前位置:  kv2[0], kv2[1]
attn1 = (q[:, :self.num_heads//2] @ k1.transpose([0, 1, 3, 2])) * self.scale
attn1 = F.softmax(attn1, axis=-1)
attn1 = self.attn_drop(attn1)
v1 = v1 + self.local_conv1(v1.transpose([0, 2, 1, 3]).reshape([B, -1, C//2]).
transpose([0, 2, 1]).reshape([B,C//2, H//self.sr_ratio, W//self.sr_ratio])).\
reshape([B, C//2, -1]).reshape([B, self.num_heads//2, C // self.num_heads, -1]).transpose([0, 1, 3, 2])
x1 = (attn1 @ v1).transpose([0, 2, 1, 3]).reshape([B, N, C//2])
attn2 = (q[:, self.num_heads // 2:] @ k2.transpose([0, 1, 3, 2])) * self.scale
attn2 = F.softmax(attn2, axis=-1)
attn2 = self.attn_drop(attn2)
v2 = v2 + self.local_conv2(v2.transpose([0, 2, 1, 3]).reshape([B, -1, C//2]).
transpose([0, 2, 1]).reshape([B, C//2, H*2//self.sr_ratio, W*2//self.sr_ratio])).\
reshape([B, C//2, -1]).reshape([B, self.num_heads//2, C // self.num_heads, -1]).transpose([0, 1, 3, 2])
x2 = (attn2 @ v2).transpose([0, 2, 1, 3]).reshape([B, N, C//2])
x = paddle.concat([x1, x2], axis=-1) else:
kv = self.kv(x).reshape([B, -1, 2, self.num_heads, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
k, v = kv[0], kv[1]
attn = (q @ k.transpose([0, 1, 3, 2])) * self.scale
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose([0, 2, 1, 3]).reshape([B, N, C]) + self.local_conv(v.transpose([0, 2, 1, 3]).reshape([B, N, C]).
transpose([0, 2, 1]).reshape([B,C, H, W])).reshape([B, C, N]).transpose([0, 2, 1])
x = self.proj(x)
x = self.proj_drop(x) return x
kv2[0], kv2[1]
attn1 = (q[:, :self.num_heads//2] @ k1.transpose([0, 1, 3, 2])) * self.scale
attn1 = F.softmax(attn1, axis=-1)
attn1 = self.attn_drop(attn1)
v1 = v1 + self.local_conv1(v1.transpose([0, 2, 1, 3]).reshape([B, -1, C//2]).
transpose([0, 2, 1]).reshape([B,C//2, H//self.sr_ratio, W//self.sr_ratio])).\
reshape([B, C//2, -1]).reshape([B, self.num_heads//2, C // self.num_heads, -1]).transpose([0, 1, 3, 2])
x1 = (attn1 @ v1).transpose([0, 2, 1, 3]).reshape([B, N, C//2])
attn2 = (q[:, self.num_heads // 2:] @ k2.transpose([0, 1, 3, 2])) * self.scale
attn2 = F.softmax(attn2, axis=-1)
attn2 = self.attn_drop(attn2)
v2 = v2 + self.local_conv2(v2.transpose([0, 2, 1, 3]).reshape([B, -1, C//2]).
transpose([0, 2, 1]).reshape([B, C//2, H*2//self.sr_ratio, W*2//self.sr_ratio])).\
reshape([B, C//2, -1]).reshape([B, self.num_heads//2, C // self.num_heads, -1]).transpose([0, 1, 3, 2])
x2 = (attn2 @ v2).transpose([0, 2, 1, 3]).reshape([B, N, C//2])
x = paddle.concat([x1, x2], axis=-1) else:
kv = self.kv(x).reshape([B, -1, 2, self.num_heads, C // self.num_heads]).transpose([2, 0, 3, 1, 4])
k, v = kv[0], kv[1]
attn = (q @ k.transpose([0, 1, 3, 2])) * self.scale
attn = F.softmax(attn, axis=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose([0, 2, 1, 3]).reshape([B, N, C]) + self.local_conv(v.transpose([0, 2, 1, 3]).reshape([B, N, C]).
transpose([0, 2, 1]).reshape([B,C, H, W])).reshape([B, C, N]).transpose([0, 2, 1])
x = self.proj(x)
x = self.proj_drop(x) return x 上一篇:
上一篇: 返回列表
返回列表