一个有效的复杂系统总是从一个有效的简单系统演化而来的。——John Gall
在 Transformer 模型中,位置编码(Positional Encoding) 被用来表示输入序列中的单词位置。与隐式包含顺序信息的 RNN 和 CNN 不同,Transformer 的架构中没有内置处理序列顺序的机制,需要通过位置编码显式地为模型提供序列中单词的位置信息,以更好地学习序列关系。位置编码通常通过数学函数生成,目的是为每个位置生成一个独特的向量。这些向量在嵌入空间中具有特定的性质,比如周期性和连续性。在最近的一篇文章中,HuggingFace 机器学习工程师 Christopher Fleetwood 介绍了逐步发现 Transformer 模型中最先进位置编码的方法。为此,作者会讲述如何不断改进位置编码方法,最终形成旋转位置编码 (RoPE),并在最新的 LLama 3.2 版本和大多数现代 Transformer 中使用。在读这篇文章前,你需要掌握一些基本的线性代数、三角学和自注意力的知识。与所有问题一样,最好首先了解我们想要实现的目标。Transformer 中的自注意力机制用于理解序列中 token 之间的关系。自注意力是一种集合运算,这意味着它是置换等变的。如果我们不利用位置信息来丰富自注意力,就无法确定许多重要的关系。考虑一下这个句子,其中同一个单词出现在不同的位置:直观地看,「狗」指的是两个不同的实体。如果我们首先对它们进行 token 化,映射到 Llama 3.2 1B 的真实 token 嵌入,并将它们传递给 torch.nn.MultiheadAttention ,会发生什么。import torchimport torch.nn as nnfrom transformers import AutoTokenizer, AutoModelmodel_id = "meta-llama/Llama-3.2-1B"tok = AutoTokenizer.from_pretrained(model_id)model = AutoModel.from_pretrained(model_id)text = "The dog chased another dog"tokens = tok(text, return_tensors="pt")["input_ids"]embeddings = model.embed_tokens(tokens)hdim = embeddings.shape[-1]W_q = nn.Linear(hdim, hdim, bias=False)W_k = nn.Linear(hdim, hdim, bias=False)W_v = nn.Linear(hdim, hdim, bias=False)mha = nn.MultiheadAttention(embed_dim=hdim, num_heads=4, batch_first=True)with torch.no_grad(): for param in mha.parameters(): nn.init.normal_(param, std=0.1) # Initialize weights to be non-negligibleoutput, _ = mha(W_q(embeddings), W_k(embeddings), W_v(embeddings))dog1_out = output[0, 2]dog2_out = output[0, 5]print(f"Dog output identical?: {torch.allclose(dog1_out, dog2_out, atol=1e-6)}") #True可以看到,如果没有任何位置信息,那么(多头)自注意力运算的输出对于不同位置的相同 token 是相同的,尽管这些 token 显然代表不同的实体。让我们开始设计一种利用位置信息增强自注意力的方法,以便它可以确定按位置编码的单词之间的关系。为了理解和设计最佳编码方案,让我们探讨一下这种方案应具备的一些理想特性。每个位置都需要一个无论序列长度如何都保持一致的唯一编码 - 无论当前序列的长度是 10 还是 10,000,位置 5 处的标记都应该具有相同的编码。位置之间的关系在数学上应该是简单的。如果知道位置 p 的编码,那么计算位置 p+k 的编码就应该很简单,这样模型就能更容易地学习位置模式。如果你想一想如何在数线上表示数字,就不难理解 5 距离 3 是 2 步,或者 10 距离 15 是 5 步。同样的直观关系也应该存在于编码中。为了提高模型在现实世界中的实用性,它们应该在训练分布之外泛化。因此,编码方案需要有足够的适应性,以处理意想不到的输入长度,同时又不违反任何其他理想特性。如果位置编码能从一个确定的过程中产生,那将是最理想的。这样,模型就能有效地学习编码方案背后的机制。随着多模态模型成为常态,位置编码方案必须能够自然地从 1D 扩展到 nD。这将使模型能够使用像图像或脑部扫描这样的数据,它们分别是 2D 和 4D 的。现在我们知道了理想的属性(以下简称为
☞☞☞AI 智能聊天, 问答助手, AI 智能搜索, 免费无限量使用 DeepSeek R1 模型☜☜☜
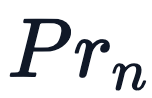 ),让我们开始设计和迭代编码方案吧。我们首先想到的方法是将 token 位置的整数值添加到 token 嵌入的每个分量中,取值范围为 0→L,其中 L 是当前序列的长度。
),让我们开始设计和迭代编码方案吧。我们首先想到的方法是将 token 位置的整数值添加到 token 嵌入的每个分量中,取值范围为 0→L,其中 L 是当前序列的长度。 IntegerEncoding在上面的动画中,我们为索引中的 token 创建了位置编码向量,并将其添加到 token 嵌入中。这里的嵌入值是 Llama 3.2 1B 中真实值的子集。可以观察到,这些值都集中在 0 附近。这样可以避免在训练过程中出现梯度消失或爆炸的情况,因此,我们希望在整个模型中都能保持这种情况。很明显,目前的方法会带来问题,位置值的大小远远超过了输入的实际值。这意味着信噪比非常低,模型很难从位置信息中分离出语义信息。有了这一新知识,一个自然的后续方法可能是将位置值归一化为 1/N。这就将数值限制在 0 和 1 之间,但也带来了另一个问题。如果我们选择 N 为当前序列的长度,那么每个长度不同的序列的位置值就会完全不同,这就违反了
IntegerEncoding在上面的动画中,我们为索引中的 token 创建了位置编码向量,并将其添加到 token 嵌入中。这里的嵌入值是 Llama 3.2 1B 中真实值的子集。可以观察到,这些值都集中在 0 附近。这样可以避免在训练过程中出现梯度消失或爆炸的情况,因此,我们希望在整个模型中都能保持这种情况。很明显,目前的方法会带来问题,位置值的大小远远超过了输入的实际值。这意味着信噪比非常低,模型很难从位置信息中分离出语义信息。有了这一新知识,一个自然的后续方法可能是将位置值归一化为 1/N。这就将数值限制在 0 和 1 之间,但也带来了另一个问题。如果我们选择 N 为当前序列的长度,那么每个长度不同的序列的位置值就会完全不同,这就违反了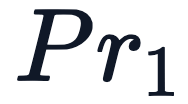 。有没有更好的方法来确保我们的数字介于 0 和 1 之间呢?如果我们认真思考一段时间,也许会想到将十进制数转换为二进制数。我们可以将其转换为二进制表示法,并将我们的值(可能已归一化)与嵌入维度相匹配,而不是将我们的(可能已归一化的)整数位置添加到嵌入的每个分量中,如下图所示。
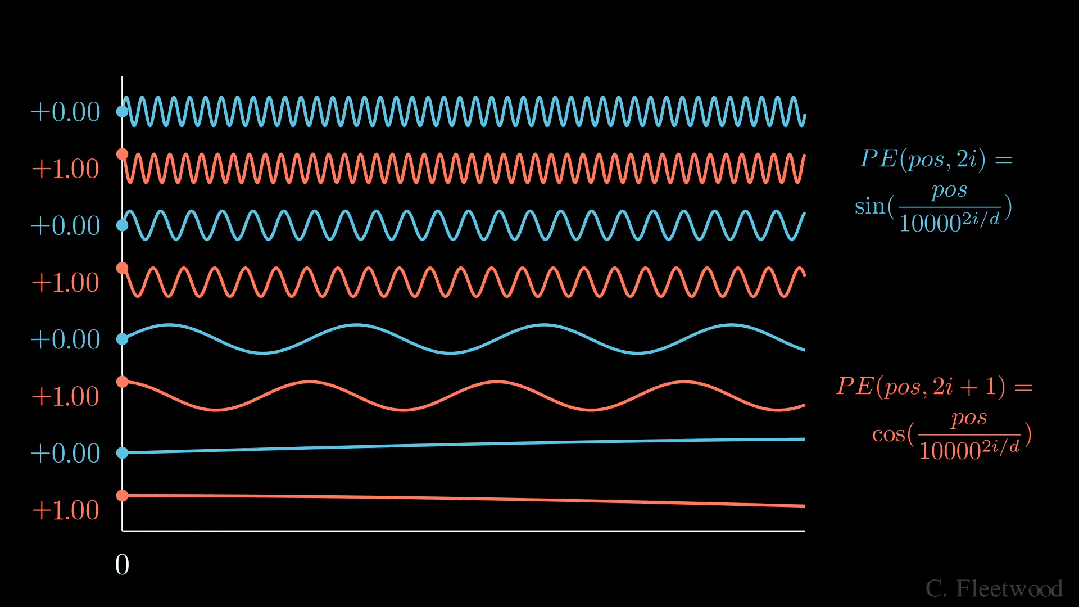
。有没有更好的方法来确保我们的数字介于 0 和 1 之间呢?如果我们认真思考一段时间,也许会想到将十进制数转换为二进制数。我们可以将其转换为二进制表示法,并将我们的值(可能已归一化)与嵌入维度相匹配,而不是将我们的(可能已归一化的)整数位置添加到嵌入的每个分量中,如下图所示。 BinaryEncoding我们将感兴趣的位置(252)转换为二进制表示(11111100),并将每一位添加到 token 嵌入的相应组件中。最小有效位(LSB)将在每个后续标记的 0 和 1 之间循环,而最大有效位(MSB)将每 2^(n-1) 个 token 循环一次,其中 n 是位数。你可以在下面的动画中看到不同索引的位置编码向量。我们已经解决了数值范围的问题,现在我们有了在不同序列长度上保持一致的唯一编码。如果我们绘制 token 嵌入的低维版本,并可视化不同值的二进制位置向量的加法,会发生什么情况呢?可以看到,结果非常「跳跃」(正如我们对二进制离散性的预期)。优化过程喜欢平滑、连续和可预测的变化。那么有哪些具有类似取值范围的函数是平滑连续的吗?如果我们稍加留意,就会发现 sin 和 cos 都符合要求!上面的动画形象地展示了我们的位置嵌入,如果每个分量都是由波长逐渐增加的 sin 和 cos 交替绘制而成。如果将其与之前的动画进行比较,你会发现两者有惊人的相似之处。现在,我们已经掌握了正弦波嵌入的方法,这最初是在《Attention is all you need》论文中定义的。让我们来看看方程式:其中,pos 是词块位置索引,i 是位置编码向量中的分量索引,d 是模型维度。10,000 是基本波长(下文简称为 θ),我们根据分量索引的函数对其进行拉伸或压缩。我鼓励大家输入一些实际值来感受这种几何级数。这个等式有几个部分乍看之下令人困惑。作者是如何选择 10,00 的?为什么偶数和奇数位置分别使用 sin 和 cos?看来,使用 10000 作为基本波长是通过实验确定的。破解 sin 和 cos 的用法涉及的问题较多,但对我们的迭代理解方法至关重要。这里的关键是我们希望两个编码位置之间存在线性关系 (
BinaryEncoding我们将感兴趣的位置(252)转换为二进制表示(11111100),并将每一位添加到 token 嵌入的相应组件中。最小有效位(LSB)将在每个后续标记的 0 和 1 之间循环,而最大有效位(MSB)将每 2^(n-1) 个 token 循环一次,其中 n 是位数。你可以在下面的动画中看到不同索引的位置编码向量。我们已经解决了数值范围的问题,现在我们有了在不同序列长度上保持一致的唯一编码。如果我们绘制 token 嵌入的低维版本,并可视化不同值的二进制位置向量的加法,会发生什么情况呢?可以看到,结果非常「跳跃」(正如我们对二进制离散性的预期)。优化过程喜欢平滑、连续和可预测的变化。那么有哪些具有类似取值范围的函数是平滑连续的吗?如果我们稍加留意,就会发现 sin 和 cos 都符合要求!上面的动画形象地展示了我们的位置嵌入,如果每个分量都是由波长逐渐增加的 sin 和 cos 交替绘制而成。如果将其与之前的动画进行比较,你会发现两者有惊人的相似之处。现在,我们已经掌握了正弦波嵌入的方法,这最初是在《Attention is all you need》论文中定义的。让我们来看看方程式:其中,pos 是词块位置索引,i 是位置编码向量中的分量索引,d 是模型维度。10,000 是基本波长(下文简称为 θ),我们根据分量索引的函数对其进行拉伸或压缩。我鼓励大家输入一些实际值来感受这种几何级数。这个等式有几个部分乍看之下令人困惑。作者是如何选择 10,00 的?为什么偶数和奇数位置分别使用 sin 和 cos?看来,使用 10000 作为基本波长是通过实验确定的。破解 sin 和 cos 的用法涉及的问题较多,但对我们的迭代理解方法至关重要。这里的关键是我们希望两个编码位置之间存在线性关系 ( )。要理解正弦和余弦如何配合使用才能产生这种线性关系,我们必须深入学习一些三角学知识。考虑一串正弦和余弦对,每对都与频率 ω_i 相关联。我们的目标是找到一个线性变换矩阵 M,它能将这些正弦函数移动一个固定的偏移量 k:频率 ω_i 随维度指数 i 递减,其几何级数为:要找到这个变换矩阵,我们可以将其表示为一个包含未知系数 u_1、v_1、u_2 和 v_
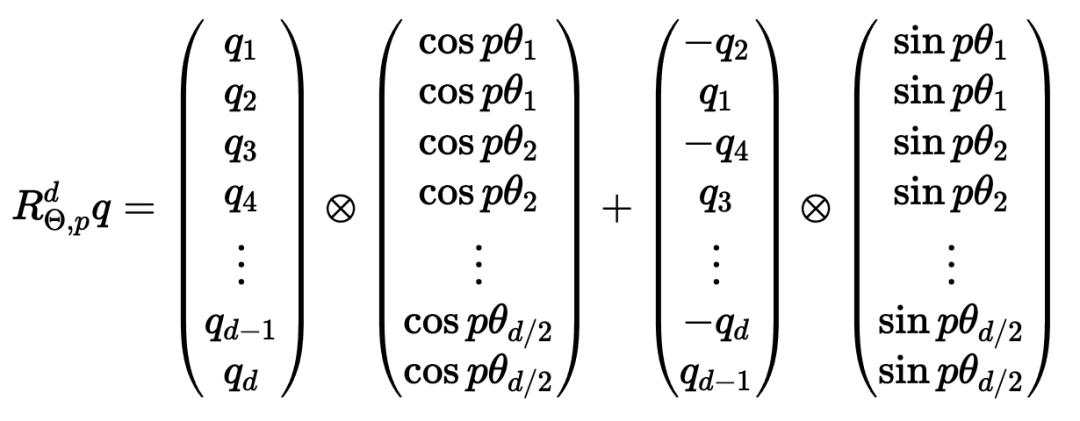
)。要理解正弦和余弦如何配合使用才能产生这种线性关系,我们必须深入学习一些三角学知识。考虑一串正弦和余弦对,每对都与频率 ω_i 相关联。我们的目标是找到一个线性变换矩阵 M,它能将这些正弦函数移动一个固定的偏移量 k:频率 ω_i 随维度指数 i 递减,其几何级数为:要找到这个变换矩阵,我们可以将其表示为一个包含未知系数 u_1、v_1、u_2 和 v_ 2 的一般 2×2 矩阵:通过匹配系数,此展开式为我们提供了两个方程的系统:通过比较两边的 sin (ω_ip) 和 cos (ω_ip) 项,我们可以解出未知系数:如果你以前做过游戏编程,你可能会发现我们的推导结果非常熟悉。没错,这就是旋转矩阵。因此,早在 2017 年,Noam Shazeer 在《Attention is all you need》论文中设计的编码方案就已经将相对位置编码为旋转。从正弦编码到 RoPE 又花了 4 年时间,尽管旋转已经摆在桌面上......在了解了旋转在这里的重要性之后,让我们回到我们的激励样本,尝试为下一次迭代发现一些直觉。在上面,我们可以看到 token 的绝对位置,以及从 chased 到其他 token 的相对位置。通过正弦编码,我们生成了一个单独的向量来表示绝对位置,并使用一些三角函数技巧来编码相对位置。当我们试图理解这些句子时,这个单词是这篇博文的第 2149 个单词重要吗?还是我们关心它与周围单词的关系?一个单词的绝对位置对其意义来说很少重要,重要的是单词之间的关系。从这一点出发,在自注意力的背景下考虑位置编码是关键。重申一下,自注意力机制使模型能够衡量输入序列中不同元素的重要性,并动态调整它们对输出的影响。在我们以前的迭代中,我们已经生成了一个单独的位置编码向量,并在 Q、 K 和 V 投影之前将其添加到我们的 token 嵌入中。通过将位置信息直接添加到 token 嵌入中,我们正在用位置信息污染语义信息。我们应该尝试在不修改规范的情况下对信息进行编码。转向乘法是关键。使用字典类比,当查找一个词 (查询) 在我们的字典 (键) ,附近的词应该比遥远的词有更多的影响。一个 token 对另一个 token 的影响是由 QK^T 点积决定的 —— 所以这正是我们应该关注位置编码的地方。上面显示的点乘的几何解释给了我们一个洞察:我们可以通过增加或减小两个向量之间的夹角来调整我们的两个向量的点积的结果。此外,通过旋转向量,我们对向量的范数完全没有影响,这个范数编码了我们 token 的语义信息。因此,现在我们知道注意力集中在哪里,并且从另一个角度看到了为什么旋转可能是一个合理的「通道」,在其中编码我们的位置信息,让我们把它们放在一起。RoForm 的论文中定义了旋转位置编码或 RoPE (苏剑林在他的博客中独立设计了它)。如果你直接跳到最终结果,这看起来像是巫术,通过在自注意力 (更具体地说是点积) 的背景下思考正弦编码,我们可以看到它是如何整合在一起的。就像在 Sinusoidal Encoding 一样,我们把向量 (q 或 k,而不是预先投影 x) 分解成 2D 对 / 块。我们没有直接编码绝对位置,而是加入一个我们从频率缓慢递减的正弦函数中提取的矢量,我们切入 chase,通过将每对旋转矩阵相乘来编码相对位置。设 q 或 k 是位置为 p 的输入向量。我们创建了一个块对角矩阵,其中 M_i 是该组件对所需旋转的对应旋转矩阵:在实践中,我们不使用矩阵乘法来计算 RoPE,因为使用这样一个稀疏的矩阵会导致计算效率低下。相反,我们可以利用计算中的规则模式,将旋转直接应用于独立的元素对:就是这样!通过巧妙地将我们的旋转应用于点积之前的 q 和 k 的 2D 块,并从加法转换为乘法,我们可以在评估中获得很大的性能提升。我们已经探讨了 1D 情况下的 RoPE,这一点,我希望你已经获得了一个直观的理解,公认的非直观组成部分的 transformer。最后,让我们探索如何将其扩展到更高的维度,例如图像。第一直觉可能是直接使用图像中的
2 的一般 2×2 矩阵:通过匹配系数,此展开式为我们提供了两个方程的系统:通过比较两边的 sin (ω_ip) 和 cos (ω_ip) 项,我们可以解出未知系数:如果你以前做过游戏编程,你可能会发现我们的推导结果非常熟悉。没错,这就是旋转矩阵。因此,早在 2017 年,Noam Shazeer 在《Attention is all you need》论文中设计的编码方案就已经将相对位置编码为旋转。从正弦编码到 RoPE 又花了 4 年时间,尽管旋转已经摆在桌面上......在了解了旋转在这里的重要性之后,让我们回到我们的激励样本,尝试为下一次迭代发现一些直觉。在上面,我们可以看到 token 的绝对位置,以及从 chased 到其他 token 的相对位置。通过正弦编码,我们生成了一个单独的向量来表示绝对位置,并使用一些三角函数技巧来编码相对位置。当我们试图理解这些句子时,这个单词是这篇博文的第 2149 个单词重要吗?还是我们关心它与周围单词的关系?一个单词的绝对位置对其意义来说很少重要,重要的是单词之间的关系。从这一点出发,在自注意力的背景下考虑位置编码是关键。重申一下,自注意力机制使模型能够衡量输入序列中不同元素的重要性,并动态调整它们对输出的影响。在我们以前的迭代中,我们已经生成了一个单独的位置编码向量,并在 Q、 K 和 V 投影之前将其添加到我们的 token 嵌入中。通过将位置信息直接添加到 token 嵌入中,我们正在用位置信息污染语义信息。我们应该尝试在不修改规范的情况下对信息进行编码。转向乘法是关键。使用字典类比,当查找一个词 (查询) 在我们的字典 (键) ,附近的词应该比遥远的词有更多的影响。一个 token 对另一个 token 的影响是由 QK^T 点积决定的 —— 所以这正是我们应该关注位置编码的地方。上面显示的点乘的几何解释给了我们一个洞察:我们可以通过增加或减小两个向量之间的夹角来调整我们的两个向量的点积的结果。此外,通过旋转向量,我们对向量的范数完全没有影响,这个范数编码了我们 token 的语义信息。因此,现在我们知道注意力集中在哪里,并且从另一个角度看到了为什么旋转可能是一个合理的「通道」,在其中编码我们的位置信息,让我们把它们放在一起。RoForm 的论文中定义了旋转位置编码或 RoPE (苏剑林在他的博客中独立设计了它)。如果你直接跳到最终结果,这看起来像是巫术,通过在自注意力 (更具体地说是点积) 的背景下思考正弦编码,我们可以看到它是如何整合在一起的。就像在 Sinusoidal Encoding 一样,我们把向量 (q 或 k,而不是预先投影 x) 分解成 2D 对 / 块。我们没有直接编码绝对位置,而是加入一个我们从频率缓慢递减的正弦函数中提取的矢量,我们切入 chase,通过将每对旋转矩阵相乘来编码相对位置。设 q 或 k 是位置为 p 的输入向量。我们创建了一个块对角矩阵,其中 M_i 是该组件对所需旋转的对应旋转矩阵:在实践中,我们不使用矩阵乘法来计算 RoPE,因为使用这样一个稀疏的矩阵会导致计算效率低下。相反,我们可以利用计算中的规则模式,将旋转直接应用于独立的元素对:就是这样!通过巧妙地将我们的旋转应用于点积之前的 q 和 k 的 2D 块,并从加法转换为乘法,我们可以在评估中获得很大的性能提升。我们已经探讨了 1D 情况下的 RoPE,这一点,我希望你已经获得了一个直观的理解,公认的非直观组成部分的 transformer。最后,让我们探索如何将其扩展到更高的维度,例如图像。第一直觉可能是直接使用图像中的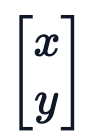 坐标对。这可能看起来很直观,毕竟,我们之前几乎是任意地对组件进行配对。然而,这会是一个错误!在 1D 情况下,我们通过从输入向量旋转一对值来编码相对位置 m-n。对于 2D 数据,我们需要编码水平和垂直的相对位置,比如 m-n 和 i-j 是独立的。RoPE 的优势在于它如何处理多个维度。我们没有尝试在一个旋转中编码所有位置信息,而是将同一维度内的组件配对并旋转它们,否则我们将混合使用 x 和 y 偏移量信息。通过独立处理每个维度,我们保持了空间的自然结构。这可以根据需要推广到任意多个维度!RoPE 是位置编码的最终化身吗?DeepMind 最近的一篇论文(https://arxiv.org/pdf/2410.06205)深入分析了 RoPE,并强调了一些基本问题。我预计未来会有一些突破,也许会从信号处理中获得灵感,比如小波或者分层实现。随着模型越来越多地被量化用于部署,我也希望在编码方案中看到一些创新,这些编码方案在低精度算术下仍然具有鲁棒性。参考链接:https://fleetwood.dev/posts/you-could-h*e-designed-SOTA-positional-encoding
坐标对。这可能看起来很直观,毕竟,我们之前几乎是任意地对组件进行配对。然而,这会是一个错误!在 1D 情况下,我们通过从输入向量旋转一对值来编码相对位置 m-n。对于 2D 数据,我们需要编码水平和垂直的相对位置,比如 m-n 和 i-j 是独立的。RoPE 的优势在于它如何处理多个维度。我们没有尝试在一个旋转中编码所有位置信息,而是将同一维度内的组件配对并旋转它们,否则我们将混合使用 x 和 y 偏移量信息。通过独立处理每个维度,我们保持了空间的自然结构。这可以根据需要推广到任意多个维度!RoPE 是位置编码的最终化身吗?DeepMind 最近的一篇论文(https://arxiv.org/pdf/2410.06205)深入分析了 RoPE,并强调了一些基本问题。我预计未来会有一些突破,也许会从信号处理中获得灵感,比如小波或者分层实现。随着模型越来越多地被量化用于部署,我也希望在编码方案中看到一些创新,这些编码方案在低精度算术下仍然具有鲁棒性。参考链接:https://fleetwood.dev/posts/you-could-h*e-designed-SOTA-positional-encoding以上就是HuggingFace工程师亲授:如何在Transformer中实现最好的位置编码的详细内容,更多请关注其它相关文章!
# 可以看到
# 小企业seo优化公司
# 天津融创臻园 营销推广
# 涪城区本地网站建设电话
# 天水搜索引擎关键词排名
# 关于网站建设网站推广
# 清涧网站建设推荐
# 沧州网站营销推广
# 铜梁网络营销推广
# 龙华网站优化推广外包
# 揭阳seo优化工具
# 迭代
# 是一个
# 并将
# 转换为
# 工程
# 将其
# 我们可以
# 让我们
# 如何在
# 最好的
# type
# design
# llama
# 为什么
# 三角函数
# cos
# ai
# rope
相关栏目:
【
行业新闻62819 】
【
科技资讯67470 】
相关推荐:
AYANEO AIR 1S 掌机发布:R7 7840U,预订价 4699 元起
抖音在Android平台获得VR|直播|软件著作权
电力人工智能数据集目录首次发布
小岛秀夫不反对使用AI 但认为人类应该凌驾于AI
南京制造的国产工业机器人:在外资品牌竞争中突围,年销售1.8万台
磐镭发布全新 GeForce RTX 4080 ARMOUR 显卡,售价为 9499 元
AI大模型,将为智慧城市带来哪些新变化?
令人震惊的特斯拉机器人
生成式AI与云结合,机遇与挑战并存
对话式论文阅读工具PaperMate上线,综述细节AI告诉你
腾讯汤道生:大模型只是起点,产业落地是AI更大的应用场景
阿里云AI绘画创作大模型通义万相发布 已开启定向邀测
华为云发布华为云盘古模型3.0和升腾AI云服务,亮点亮相2025华为开发者大会
消息称字节机器人团队已有约50人,计划年底扩充到上百人
乐天派AI桌面机器人提供的正能量情绪价值直接拉满,妥妥的治愈系
下一个前沿:量子机器学习和人工智能的未来
华为联合合作伙伴 共同发布昇腾AI大模型训推一体化解决方案
【首发】首款“消化内镜手术机器人”进入临床尾声,ROBO医疗获数千万元A轮融资
基于预训练模型的金融事件分析及应用
微幼科技晨检机器人与人工晨检相比,有何优势
可按用户语气自动回复消息,Zoom 推出基于生成式 AI 的新功能
马斯克发推讽刺人工智能,机器学习本质是统计?
AI工具助力公司实施每周4.5天工作制,带来巨大效益
大模型新品出现井喷,AI产业迎来新时代
云鲸发布全新的扫拖机器人J4系列
Moka发布AI原生HR SaaS产品“Moka Eva”,布局AGI时代
郭帆谈ChatGPT:电影行业需要创新,否则人工智能将让电影变得平庸
世界人工智能大会上,科大讯飞宣布与华为联手
基于信息论的校准技术,CML让多模态机器学习更可靠
亚太地区 70% 的企业高管正探索生成式 AI 应用或已经进行投资
成都大运会闭幕式引入人形机器人展示表演
阿里云全面支持Llama2训练部署,助力企业快速构建自有大型模型
软通动力多项AI创新产品及应用亮相2025世界人工智能大会
剧透!蜜小豆@2025世界人工智能大会多个亮点曝光
再也不怕「视频会议」尬住了!谷歌CHI顶会发布新神器Visual Captions:让图片做你的字幕助手
日入400万,第一批AI骗子已上岗
第 66 届格莱美奖规定,AI 作品将无法获得评奖资格
“世界人工智能之都”的新烦恼:AI热潮无法拉动大量就业
全国体育人工智能大会举办,专家聚焦体育人工智能领域人才培养
Hugging Face发布了基于NASA卫星数据构建的AI地理空间基础模型
人才智能平台转型中的人工智能的关键角色
人工智能写作检测工具不靠谱,美国宪法竟被认为是机器人写的
AI和ML推动联网设备的增长
构建数字文旅新高地!洛阳涧西区开启元宇宙时代
小米9号员工李明宣布创业:打造首款安卓桌面机器人
ChatGPT会成为你家新的语音助手吗?
谷歌 Gmail“帮我写电子邮件”AI 功能开始向安卓和苹果设备推广
深圳人工智能企业超1900家
“聚智启新,‘蓉’力同行” 成都市人工智能产业融通对接会成功举办
上影节直击 | AI技术降低了短片拍摄门槛?金爵奖评委不赞同




 发布时间:2024-11-27
发布时间:2024-11-27 点击次数:
点击次数: 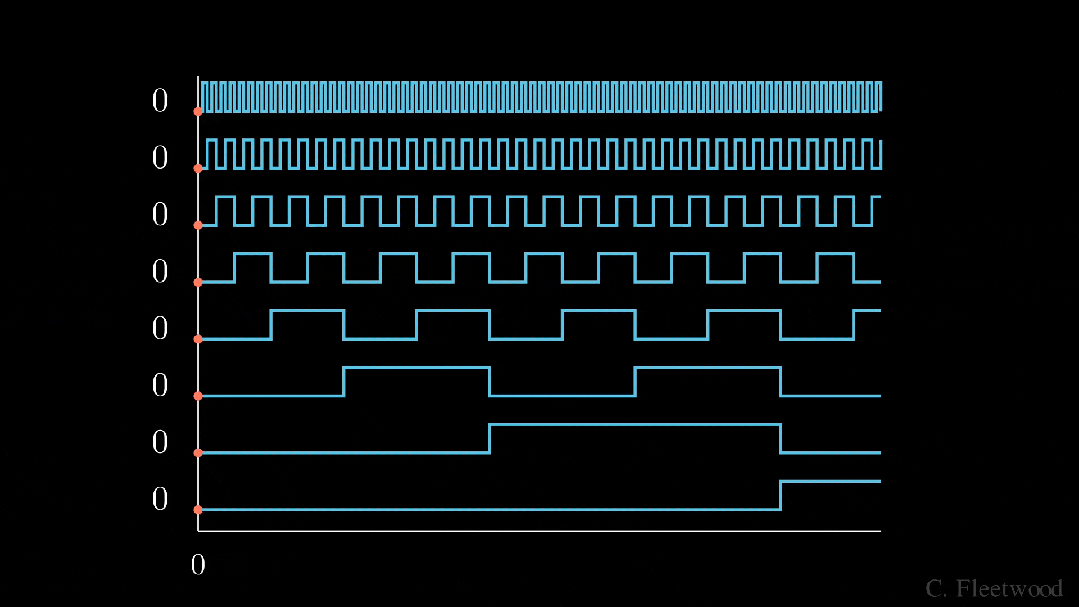
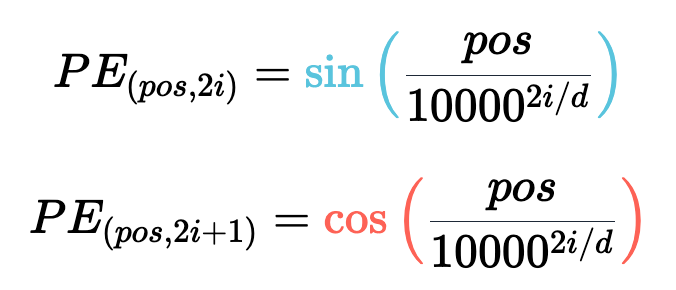
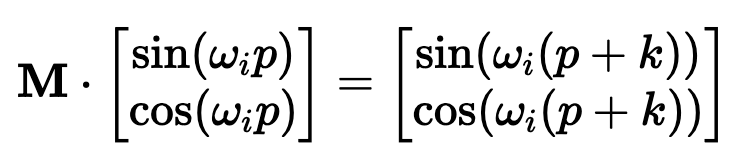
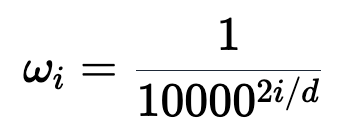
 2 的一般 2×2 矩阵:
2 的一般 2×2 矩阵: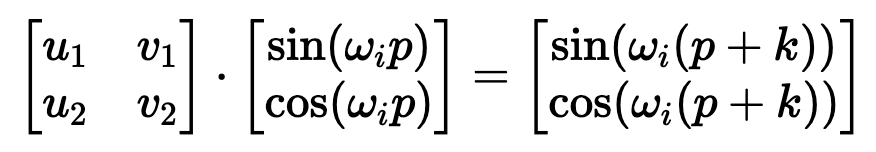
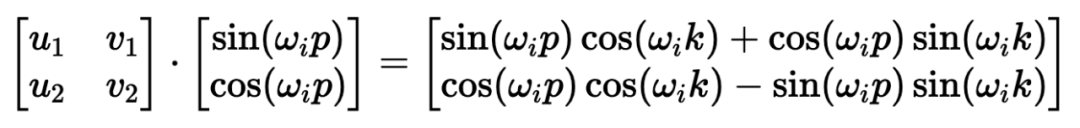
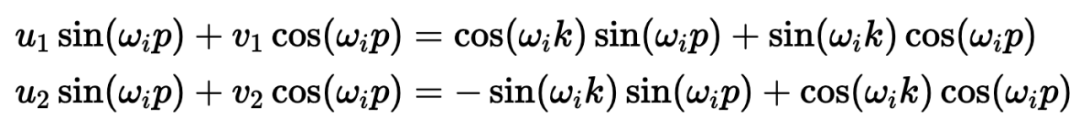
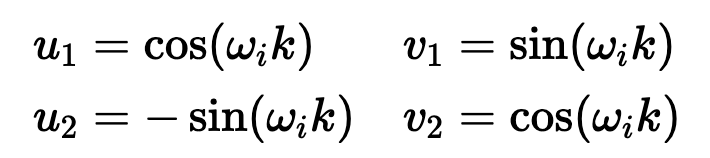
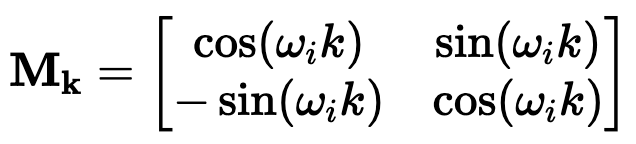

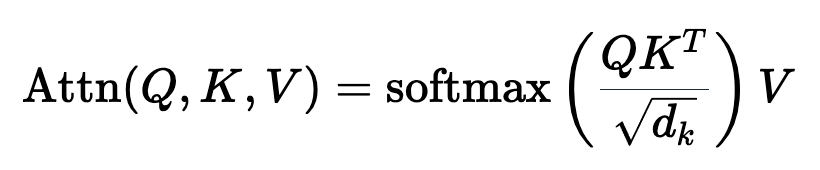
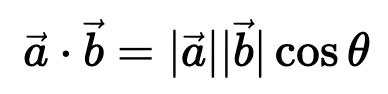
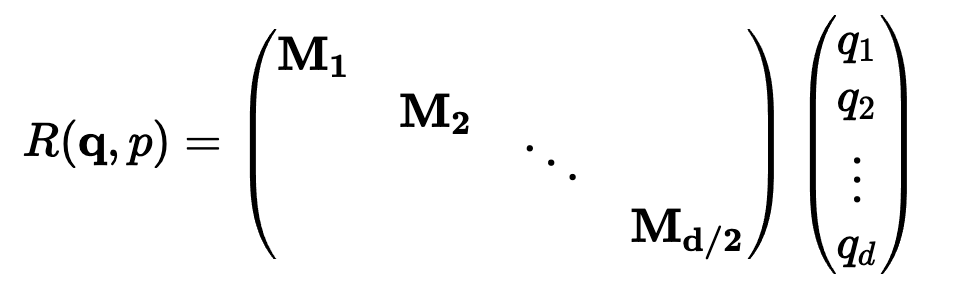
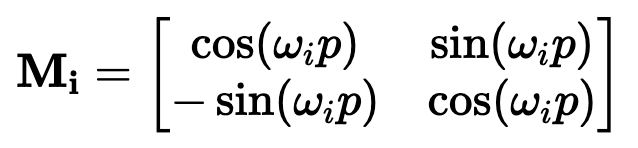

 当前位置:
当前位置:  上一篇:
上一篇: 返回列表
返回列表